Semantic date parsing¶
__author__ = "Christopher Potts"
__version__ = "CS224u, Stanford, Spring 2016 term"
Set-up¶
Make sure the
sys.path.appendvalue is the path to your local SippyCup repository. (Alternatively, you can add SippyCup to your Python path; see one of the teaching team if you'd like to do that but aren't sure how.)Make sure that
semparse_dateparse_data.pickleis in the current directory (or available via your Python path).
import sys
sys.path.append('../sippycup')
import sys
import re
import calendar
import itertools
import pickle
import random
from copy import copy
from collections import defaultdict
from datetime import date
from dateutil import parser
Goals¶
The goal of this bake-off is to train a semantic parser to interpret date strings. Although this requires only simple syntactic structures, it turns out to be a deep understanding challenge involving contextual inference. Date strings are often ambiguous, and there are conventions for how to resolve the ambiguities. For example, 1/2/11 is ambiguous between Jan 2 and Feb 1, and the 11 could pick out 1211, 1911, 2011, and so forth.
The codelab is structured basically as our last one was: the first goal is to create a grammar that gets perfect oracle accuracy, and the second goal is to design features that resolve ambiguities accurately and so predict the correct denotations.
In this case, it's possible to write a high-quality grammar right from the start. We know (approximately) what most of the words mean, so we really just need to handle the variation in the forms people use. The bigger challenge comes in defining features that capture the subtler interpretive conventions.
For reference, I've included at the bottom of the codelab a baseline: the rule-based dateutil.parser.parse. It's good, achieving around 70% on the train and dev sets. However, there are some strings that it just can't parse, and, since it isn't learning-based, it can't learn the conventions latent in the data. You'll be able to do much better!
In-class bake-off¶
Your bake-off entry is your denotation accuracy result for the dev set after training on the train set.
Data set¶
The data set has train and dev portions, with 1000 and 500 examples, respectively.
from example import Example
data = pickle.load(open('semparse_dateparse_data.pickle', 'rb'))
train = data['train']
dev = data['dev']
Here's a look at the data via random samples. Running this cell a few times will give you a feel for the data.
All the punctuation has been removed from the strings for convenience.
All of the examples end with one of two informal timezone flags:
USif the string comes from text produced in the U.S., andnon-USotherwise. This is an important piece of information that can be used in learning, since (I assume) only Americans use the jumbledmonth/day/yearorder.
# Display a random sample of training examples:
for ex in random.sample(train, k=5):
print("=" * 70)
print("Input:", ex.input)
print("Denotation:", repr(ex.denotation))
Core interpretive functionality¶
Here's the semantics you'll want to use. You won't need to change it.
Important: date_semantics expects its arguments in international order: year, month, day.
def date_semantics(year, month, day):
"""Interpret the arguments as a date objects if possible. Returns
None of the datetime module won't treat the arguments as a date
(say, because it would be a Feb 31)."""
try:
return date(year=year, month=month, day=day)
except ValueError:
return None
# The key dt is arbitrary, but the grammar rules need to hook into it.
ops = {'dt': date_semantics}
def execute(semantics):
"""The usual SippyCup interpretation function"""
if isinstance(semantics, tuple):
op = ops[semantics[0]]
args = [execute(arg) for arg in semantics[1:]]
return op(*args)
else:
return semantics
Build a grammar¶
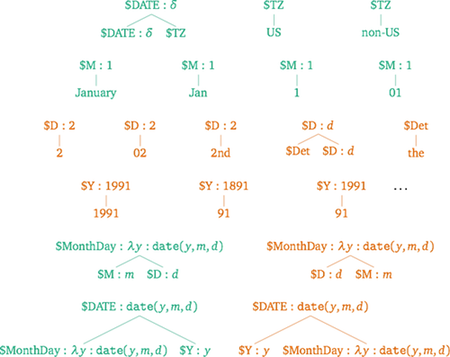
TO DO: Fill out this starter code to build your grammar. The following is a high-level summary of the grammar you're trying to build. (You might end up making slightly different assumptions, but this represents a good default goal.) This image is available in higher resolution here. Rules in green have been completed for you. Rules in orange still need to be written.
from parsing import Grammar, Rule, add_rule
# Use $DATE for the root node of its full date expressions:
gram = Grammar(start_symbol="$DATE")
# Fill this with Rule objects:
rules = []
# Make sure the grammar can handle final timezone information:
timezone_rules = [
Rule('$DATE', '$DATE $TZ', (lambda sems : sems[0])),
Rule('$TZ', 'US'),
Rule('$TZ', 'non-US') ]
rules += timezone_rules
######################################################################
#################### RULES FOR MONTHS (COMPLETED) ####################
#
# As a reminder about the notation, concepts, etc., here are lexical
# rules for the months. They all determine trees
#
# $M : i
# |
# monthname
#
# where monthname is the ith month of the year.
# Full month names with "" in the 0th position so that 'January' has
# index 1, 'February' index 2, ...
months = [str(s) for s in calendar.month_name]
# Add the rules:
rules += [Rule('$M', m, i) for i, m in enumerate(months) if m]
# 3-letter month names like "Jan", "Feb", with "" in 0th position:
mos = [str(s) for s in calendar.month_abbr]
# Add the rules:
rules += [Rule('$M', m, i) for i, m in enumerate(mos) if m]
# Numerical months:
num_months = [str(i) for i in range(1, 13)]
# Add the rules:
rules += [Rule('$M', m, int(m)) for m in num_months]
# 1-digit months with an initial zero:
num_months_padded = [str(i).zfill(2) for i in range(1,10)]
# Add the rules:
rules += [Rule('$M', m, int(m)) for m in num_months_padded]
######################################################################
####################### ADD RULES FOR THE DAYS #######################
#
# Add lexical rules for the days. Again, these will be structures
#
# $D : i
# |
# day
#
# where day is a 1- or 2-digit string and i is its corresponding int.
# Here are days of the month without and with two-digit padding. Each
# day string m can be interpreted semantically as int(m).
days = [str(d) for d in range(1, 32)]
days_padded = [str(i).zfill(2) for i in range(1, 11)]
# Add to the rules list here:
######################################################################
################## ADD RULES FOR THE ORDINAL DAYS ####################
#
# The data contain day names like "2nd". Use int2ordinal to create
# rules for these too:
#
# $D : int(i)
# |
# int2ordinal(i)
def int2ordinal(s):
"""Forms numerals like "1st" from int strs like 1"""
suffixes = {"1": "st", "2": "nd", "3": "rd"}
if len(s) == 2 and s[0] == '1': # teens
suff = "th"
else: # all others use suffixes or default to "th"
suff = suffixes.get(s[-1], "th")
return s + suff
# Add to the rules list here:
######################################################################
##################### ADD RULES TO HANDLE 'the' ######################
#
# The data contain expressions like "the 3rd". Add a lexical rule to
# include 'the' and a binary combination rule so that we have
# structures like
#
# $D
# / \
# $Det $D
# | |
# the 3rd
# Add to the rules list here:
######################################################################
################## ADD RULES FOR THE 4-DIGIT YEARS ##################
#
# Long (4-digit) years are easy: they can be interpeted as themselves.
# So these are rules of the form
#
# $Y : int(year)
# |
# year
#
# where year is a 4-digit string.
# This range will be fine for our data:
years_long = [str(y) for y in range(1900, 2100)]
# Add to the rules list here:
######################################################################
################## ADD RULES FOR THE 2-DIGIT YEARS ###################
#
# 2-digit years are ambiguous about their century. Intuitively, for
# each 2-digit year, we need a rule for interpreting it in all
# potential centuries:
# All 2-digit years:
years_short = [str(x).zfill(2) for x in range(0, 100)]
# A suitable range of century multipliers given our data:
centuries = range(1700, 2500, 100)
# Add to the rules list here:
######################################################################
####################### ADD COMPOSITION RULES ########################
#
# Here are some initial composition rules. Together, these rules
# create structures like this:
#
# $DATE
# / \
# $MonthDay $Y
# / \
# $M $D
#
# and the 'dt' key connects with the ops dictionary we defined above.
# The semantics is creating a tuple (dt year month day) for the
# sake of date_semantics. You'll clearly need rules for at least
#
# * $MonthDay in the reverse order
# * $Y before $MonthDay
composition_rules = [
# $M $D
Rule('$MonthDay', '$M $D', lambda sems : ('dt', sems[0], sems[1])),
# dt $Y $M $D
Rule('$DATE', '$MonthDay $Y', lambda sems: (sems[0][0], sems[1], sems[0][1], sems[0][2]))
]
# Add to composition_rules here:
rules += composition_rules
# Add all the rules to the grammar:
for rule in rules:
add_rule(gram, rule)
print('Grammar now has %s lexical rules, %s unary rules, and %s binary rules' % \
(len(gram.lexical_rules), len(gram.unary_rules), len(gram.binary_rules)))
It can be informative to enter your own date strings and see what happens to them:
from parsing import parse_to_pretty_string
def parse_and_interpret(s, grammar=gram):
for i, parse in enumerate(gram.parse_input(s)):
print("=" * 70)
print("Parse %s:" % (i+1), parse_to_pretty_string(parse))
print("Denotation:", execute(parse.semantics))
parse_and_interpret("5 4 2015 US")
Check oracle accuracy¶
You should be able to get 100% oracle accuracy with your grammar:
def check_oracle_accuracy(grammar=None, examples=train, verbose=True):
"""Use verbose=True to print out cases where your grammar can't
find a correct denotation among all of its parses."""
oracle = 0
for ex in examples:
# All the denotations for all the parses:
dens = [execute(parse.semantics) for parse in gram.parse_input(ex.input)]
if ex.denotation in dens:
oracle += 1
elif verbose:
print("=" * 70)
print(ex.input)
print(set(dens))
print(repr(ex.denotation))
percent_correct = (oracle/float(len(examples)))*100
print("Oracle accuracy: %s / %s (%0.1f%%)" % (oracle, len(examples), percent_correct))
check_oracle_accuracy(grammar=gram, examples=train, verbose=False)
Define features¶
If you now have perfect (or at least high) oracle accuracy, then you can begin training effective date-interpreting models.
Here's some space for inspecting parses to see how to get good features from them:
parse = gram.parse_input("2015 05 04 US")[0]
print(parse)
# Here's how to get the timezone string:
print(parse.children[1].rule.rhs[0])
# Here's how to get the top-level $Y vs. $MonthDay ordering:
print(parse.children[0].rule.rhs)
# Here's how to get the $MonthDay child names:
print(parse.children[0].children[1].rule.rhs)
def lemmas(parse):
"""Returns a list of (category, word) pairs"""
labs = []
for t in parse.children:
if len(t.rule.rhs) == 1:
labs.append((t.rule.lhs, t.rule.rhs[0]))
else:
labs += lemmas(t)
return labs
print(lemmas(parse))
TO DO: extend date_features to capture more properties of the input, the denotation, and/or how they relate to each other.
from scoring import Model
def date_rule_features(parse):
features = defaultdict(float)
# This is the timezone string:
tz = parse.children[1].rule.rhs[0]
return features
model = Model(grammar=gram, feature_fn=date_rule_features, executor=execute)
Train a model¶
The training step (feel free to fiddle — longer optimization, lower learning rate):
from learning import latent_sgd
from metrics import DenotationAccuracyMetric
trained_model = latent_sgd(
model,
train,
training_metric=DenotationAccuracyMetric(),
T=10,
eta=0.1)
Inspect the trained model¶
Which examples are you getting wrong?
def sample_errors(model=None, dataset=None, k=5):
data = copy(dataset)
random.shuffle(data)
errors = 0
for i in range(len(data)):
ex = data[i]
parses = model.parse_input(ex.input)
if not parses or (parses[0].denotation != ex.denotation):
best_parse = parses[0] if parses else None
prediction = parses[0].denotation if parses else None
print("=" * 70)
print('Input:', ex.input)
print('Best parse:', best_parse)
print('Prediction:', prediction)
print('Actual:', ex.denotation)
errors += 1
if errors >= k:
return
sample_errors(model=trained_model, dataset=train)
Evaluate the trained model¶
Now evaluate your model on the held-out data. Turn in your 'denotation accuracy' value for the bake-off.
from experiment import evaluate_model
from metrics import denotation_match_metrics
evaluate_model(
model=trained_model,
examples=dev,
examples_label="Dev",
metrics=denotation_match_metrics(),
print_examples=False)
Appendix: a rule-based baseline¶
Was it worth the trouble? I think it was, in that you probably soundly beat the high-performance dateutil parser.
def evaluate_dateutil(dataset=data['dev'], verbose=False):
"""dataset should be one data['train'] or data['dev']. Use
verbose=True to see information about the errors."""
results = defaultdict(int)
for ex in dataset:
input = re.sub(r"(non-)?US$", "", ex.input)
prediction = None
try:
prediction = parser.parse(input).date()
except ValueError:
if verbose:
print("dateutil can't parse '%s'" % input)
results[prediction == ex.denotation] += 1
if prediction and prediction != ex.denotation and verbose:
print("dateutil predicted %s to mean %s" % (input, repr(prediction)))
acc = (results[True] / float(len(dataset)))*100
return "accuracy: %s / %s (%0.1f%%)" % (results[True], len(dataset), acc)
# Use verbose=True to see where and how dateutil stumbles:
for key in ('train', 'dev'):
print(key, evaluate_dateutil(dataset=data[key], verbose=False))