
R для тервера и матстата.
6.3 Проверка гипотез. Поющие коты и AБ-тесты.
6.3 Проверка гипотез. Поющие коты и AБ-тесты.
Данный ноутбук является конспектом по курсу «R для теории вероятностей и математической статистики» (РАНХиГС, 2017-2018). Автор ноутбука вот этот парень по имени Филипп. Если у вас для него есть деньги, слава или женщины, он от этого всего не откажется. Ноутбук распространяется на условиях лицензии Creative Commons Attribution-Share Alike 4.0. При использовании обязательно упоминание автора курса и аффилиации. При наличии технической возможности необходимо также указать активную гиперссылку на страницу курса. На ней можно найти другие материалы. Фрагменты кода, включенные в этот notebook, публикуются как общественное достояние.
В этой тетрадке мы посмотрим чего эдакого рисёрчеры в крупных компаниях проверяют на ежедневной основе. Делать это мы будем на примере поющих котов.
1. В целом про АБ-тесты¶
Этот параграф писался на основе вот этой виньетки.
Во всех сферах бизнеса постоянно требуется улучшать его ключевые показатели. Идеи улучшения могут быть совершенно разными. Обычно их очень много. Хочется проверить какие из них будут работать, а какие нет. Тестировать идеи нужно на реальных пользователях. Выделяется группа пользователей, которой показывается некоторое новшество. Когда наберётся достаточно информации, проверяется гипотеза об улучшении ключевой метрики. Схема такой проверки называется A/Б-тестом.
Что за улучшение и метрики¶
Итак, мы придумали идею, которая должна улучшить мир. Чтобы сделать вывод реально ли улучшает наша идея мир, мы должны выбрать какой-то показатель и посмотреть вырастет он или упадёт. Такие показатели называются метриками. Чаще всего при проведении А/Б-теста мы пытаемся понять улучшилось ли состояние бизнеса и поэтому используем метрики, связанные с деньгами.
Например, увеличились ли продажи, когда мы изменили алгоритм рекомендации товаров. Стали ли люди донатить больше денег, когда мы усложнили прохождение уровня в игре. Выросли ли продажи, когда мы провели маркетинговую компанию и тп.
Метрики, связанные с деньгами бывают очень грубыми. Они могут слабо реагировать на небольшие изменения или после внесения изменений может потребоваться очень много времени, чтобы измерить их. Из-за этого часто используют промежуточные метрики, который, с одной стороны достаточно чувствительны к изменениям, а с другой, хорошо согласуются с бизнес-показателями, которые в реальности требуется измерить. Например, при внесении изменений на сайт с арендой квартир в качестве такой метрики можно взять "среднее количество визитов на сайт в день" или "среднее число уникальных пользователей" или "количество репостов сайта в социальных сетях".
Где используются А/Б тесты¶
- Любые сайты, независимо от их профиля, используют механизм A/Б-тестирования для принятия решения о внесении каких-то изменений. Аналогично тестируются любые изменения дизайна или функциональности в приложениях или играх.
- Работоспособность лекарств. Тех, кто согласен принять участие в тесте, делят на две части. Одной дают плацебо, другой реальное лекарство. После смотрят какая доля людей в обеих группах поправилась и делают выводы об эффективности.
- Перед тем как автоматизировать какой-то процесс с помощью алгоритма машинного обучения, всегда проверяется с помощью А/Б-теста будет ли он работать в реальности лучше, чем человек.
- А/Б-тестирование встречается и в довольно неожиданных местах. При правительствах США и Великобритани есть небольшие группы, которые совместно с психологами-бихевиористами выдвигают гипотезы о том, как люди взаимодействуют с государством, и на основании таких гипотез проводятся эксперименты: например, небольшие изменения в дизайне налоговой формы, или изменения в способе записи на донорство или трансплантацию органов. Такие вещи, которые легко и очень дешево можно поменять, оказывается, приводят к тому, что государство может сэкономить миллионы.
Кекс про кока-колу¶
Компания, выпускающая колу решила протестировать как повлияет на продажи увеличение количества сахара в напитке. Для этого была собрана фокус-группа, которой предложили на выбор два напитка: со стандартным содержанием сахара и увеличенным. Людям нужно было попробовать оба и выбрать тот, который им больше понравился. В результате этого исследования выяснилось, что большее количество людей предпочитает Кока-Колу с увеличенным количеством сахара. Было решено увеличить количество сахара в напитке для более широкой аудитории. Неожиданно продажи упали. Вопрос: что пошло не так?
Ответ: Эксперты стали разбираться почему так произошло, ведь в рамках фокус-группы было показано, что больше сахара — это вкуснее. Выяснилось, что это исследование проходило не в тех самых условиях, в которых люди обычно пьют Кока-Колу. Если речь идёт всего лишь об одном стакане, то, действительно, людям нравится большее количество сахара. Однако если напиток употребляется постоянно в больших количествах, то больше сахара — хуже. Кажется, что это логично: сложно выпить большое количество очень сладкого напитка. Поэтому, когда проводятся исследования на фокус-группах, нужно следить за тем, чтобы условия были максимально приближены к настоящим.
Мораль: любые исследования, которые проводятся в реальности стоят денег и могут привести к потерям. Тестирование идей должно происходить в максимально приближённых к реальности условиях.
Подводные камни¶
В целом, процесс A/Б-тестирования распадается на две большие части. Первая часть — это планирование эксперимента: как именно будет выглядеть A/Б-тест, как пользователей будут делить на группы, сколько будет длиться тест и многие другие вопросы, связанные с этим. Вторая часть — это непосредственно проверка гипотез, принятие решения о том, положительно или отрицательно влияют изменения на бизнес в целом. На этапе дизайна возникает огромное количество проблем.
Мы уже обсудили первый подводный камень: любые изменения должны тестироваться в максимально приближенных к реальности условиях. Иначе можно потерпеть фиаско аналогичное Кока-Коле.
Есть и другие проблемы. Например, всегда хочется как можно меньше времени тратить на эксперименты и проверить много идей сразу. В такой ситуации будет сложно понять какое именно изменение привело к улучшению. Нужно следить, чтобы один и тот же пользователь не попал сразу в несколько экспериментальных групп.
Более того, может оказаться, что изменения взаимоуничтожают друг-друга. Одно улучшает метрики, второе всё портит. Если проводится много экспериментов сразу, нужно следить за тем, чтобы они не противоречили друг-другу. Например, известна история о том, как Google тестировал 41 оттенок синего в цвете ссылок в поисковой выдаче. Если допустить, что одновременно еще проводился бы эксперимент о том, как выбрать цвет страницы или цвет, на фоне которого показываются эти ссылки, очевидно, что они не должны быть тех же самых цветов, что и текст ссылок, иначе пользователь просто не сможет ничего прочитать. То есть пример подбора одновременно цвета текста и цвета фона, на котором он показывается, — это пример экспериментов, которые друг с другом не сочетаются.
Для проведения эксперимента требуется небольшая группа пользователей, которой будут показаны изменения. Для того, чтобы результаты, полученные на этой группе, можно было обобщить на всю выборку, она должна быть репрезентативной. Мы уже обсуждали до этого чем череваты проблемы с выборками в плане оценок параметров. Те же проблемы всплывают и тут. С одной стороны экспериментальная группа должна быть рандомизирована. С другой стороны в ней должна быть сохранена стратификация. Так, если известно, что 2/3 пользователей продукта - женщины, то в экспериментальной группе должно быть 2/3 женщин. При дизайне эксперимента между двумя этими вещами должен быть сохранён баланс. При этом не стоит забывать про закон больших чисел. Если в выборке довольно много людей, то, скорее всего, она охватит все страты в нужных пропрорциях.
Эксперимент может ставиться на одних и тех же пользователях. Может оказаться важным как один и тот же пользователь реагирует на товар без изменений и с изменениями. Как вы помните, такие выборки называются связными. Возможно, что важен порядок предъевляемых изменений. Для того, чтобы понять влияние порядка изменений, можно попробовать использовать дизайн крест-накрест: половине пользователей показать сначала новый вариант, потом - старый, а другой половине - наоборот.
Можно увидеть изменения там, где их нет. Например, если произошла выкатка на сайт новой кнопки, пользователи могут начать тыкать на неё из-за того, что они удивились новому изменению и хотят проверить что произойдёт. Мы при этом можем обрадоваться тому, что количество кликов увеличилось и решить, что это принесёт нам денег. Такую штуку можно детектировать с помощью обратного эксперимента. Пусть мы выкатили новую версию кнопки. Она показала себя лучше. Давайте расширим её до более большого числа пользователей, но при этом какой-то узкой группе людей продолжим показывать старую версию. Когда ажиотаж из-за любопытства стихнет, мы сможем удостовериться, что число кликов выросло из-за дизайна, проведя на длинном горизонте повторный А/Б-тест.
Как мы с вами только что убедились, при проверке гипотез можно встреться с подводными камнями вообще везде. Иногда для того, чтобы определить насколько хорошим получился дизайн эксперимента, используют А/А-тест. Технология такого тестированя работает следующим образом: пользователей делят на две группы в соответствии с дизайном и показывают обеим группам старый вариант. Далее проверяют гипотезу о том, что метрики в группах совпадают. Если гипотеза не отвергается, всё круто. Если видны значимые изменения в метриках, у нашего дизайна есть проблемы.
Размер выборки¶
Итак, дизайн эксперимента разработан, метрики выбраны. Вся экспериментальная структура устойчива и готова к пуску эксеримента. Осталось только решить сколько человек брать в выборку и как долго тест должен длиться.
Задача определения объёма выборки тесто связана с тем, какой именно статистический инструмент будет использоваться для тестирования. Для каждого критерия подбор объёма осуществляется своим способом.
Обычно, нужно понять какой минимальный размер эффекта мы хотим детектировать. Далее мы должны выбрать уровень значимости и размер ошибки второго рода. Далее, если взять статистический критерий и выразить из него величину $n$, можно понять при каких объёмах выборки этот размер будет улавливаться как значимый. Для различных критериев существуют калькуляторы мощности, в которые можно внести зафиксированные величины и получить на выход неизвестные.
2. О котах и печеньках¶
Давайте посмотрим на данные одной мобильной игрушки под названием "Cookie Cats", разработанной компанией Tactile Entertainment. Это стандартный match-three пазл, где игрокам нужно соединять элементы одинаковых цветов, чтобы очистить поле и выиграть на уровне. И еще там есть поющие коты. Это важно.
По мере того, как игроки проходят уровни, они встречают ворота-блокеры, которые вынуждают их либо ждать длительное время, либо совершить внутриигровую покупку, чтобы продолжить играть. Помимо того, что эти ворота приносят разработчикам деньги от покупок, они еще и вынуждают игроков делать перерыв, в надежде на то, что те вернутся с новыми силами и снова начнут получать удовольствие от котиков.
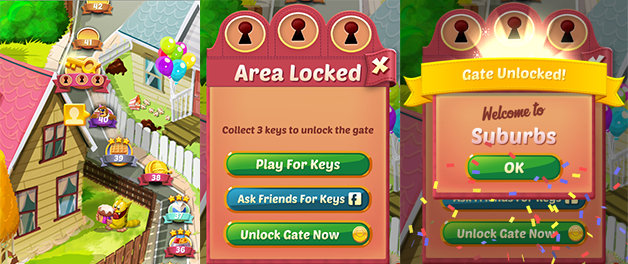
Но возникает вопрос - когда и где ставить эти ворота? Изначально первые ворота стояли на 30-м уровне игры, однако в этом ноутбуке мы будем анализировать АБ-тест, в котором разработчики передвинули ворота на 40-й уровень. В частности мы будем смотреть влияние этого изменения на такой важный показатель как "retention" или удержание игроков, который расчитывается как отношение уникальных игроков, зашедших в игру на 1-й, 2-й, ... N-й день после установки ко всем игрокам, установившим приложение в этот день. Данные можно скачать по ссылке.
library('dplyr') # библиотека для работы с таблицами
# Загружаем табличку с данными
df = read.csv('/Users/fulyankin/Yandex.Disk.localized/R/R_prob_data/cookie_cats.csv', sep=',', dec='.',
colClasses=c("retention_1"='logical',"retention_7"='logical'))
head(df, 5) # шапка таблицы
| userid | version | sum_gamerounds | retention_1 | retention_7 |
|---|---|---|---|---|
| 116 | gate_30 | 3 | FALSE | FALSE |
| 337 | gate_30 | 38 | TRUE | FALSE |
| 377 | gate_40 | 165 | TRUE | FALSE |
| 483 | gate_40 | 1 | FALSE | FALSE |
| 488 | gate_40 | 179 | TRUE | TRUE |
dim(df) # размер таблицы
- 90189
- 5
3. Данные для АБ-теста¶
Итак, собраны данные по 90189 игрокам, которые установили игру во время запущенного теста. У нас есть следующие переменные:
userid- уникальный номер, идентифицирующий каждого игрока.version- был ли пользователь отнесен к контрольной группе (gate_30- ворота на 30-м уровне) или к тестовой (gate_40- ворота на 40-м уровне).sum_gamerounds- число сессий, сыгранных игроком в течение первых 14 дней после установки игры.retention_1- вернулся ли игрок после первого дня с момента установки?retention_7- вернулся ли игрок после седьмого дня с момента установки?
Когда игрок устанавливает игру, он/она случайным образом относятся либо к группе gate_30, либо gate_40. На всякий случай, давайте проверим, действительно ли их примерно поровну в каждой из группу.
df %>% group_by(version) %>% summarise(n = n())
| version | n |
|---|---|
| gate_30 | 44700 |
| gate_40 | 45489 |
4. Распределение числа игровых сессий¶

Похоже, что игроков действительно примерно поровну в каждой из групп, отлично!
Фокус нашего анализа будет сосредоточен на удержании игроков (retention), но ради интереса давайте построим распределение числа игровых сессий, сыгранных игроками в течение их первой недели жизни в игре.
library('ggplot2') # Пакет для картинок
# Подсчитываем число людей, сыгравших каждое количество раундов
plot_df = df %>% group_by(sum_gamerounds) %>% summarise(number_of_players = n())
head(plot_df,5)
| sum_gamerounds | number_of_players |
|---|---|
| 0 | 3994 |
| 1 | 5538 |
| 2 | 4606 |
| 3 | 3958 |
| 4 | 3629 |
# Рисуем распределение этих людей
options(repr.plot.width=6, repr.plot.height=3)
ggplot(plot_df[1:100,], aes(x=sum_gamerounds, y=number_of_players))+
geom_line()

5. Общее удержание первого дня (1-day retention)¶
На графике вверху мы видим, что некоторые игроки установили игру, но даже ни разу не поиграли (0 сессий), многие игроки закончили лишь пару сессий за первую неделю, а некоторые действительно подсели и сыграли более 80 раз!
Конечно, мы хотим, чтобы игроки были заинтересованы в игрушке и возвращались в неё снова и снова. Обычная метрика, использующаяся в гейм-индустрии, чтобы измерить, насколько игрушка веселая и захватывающая, - это удержание первого дня (1-day retention): Процент игроков, которые вренулись и снова стали играть спустя 1 день после установки. Чем выше удержание первого дня, тем проще и дальше удерживать пользователей и строить себе большую базу фанатов.
В качестве первого шага, давайте посмотрим, как в целом выглядит 1-day retention.
mean(df$retention_1)
6. 1-day retention по АБ-группам¶

Итак, немногим меьше половины всех игроков возвращяются к нам спустя один день после установки. Теперь давайте посмотрим, как отличается 1-day retention внутри наших тестовых групп.
df %>% group_by(version) %>% summarise(mean(retention_1))
| version | mean(retention_1) |
|---|---|
| gate_30 | 0.4481879 |
| gate_40 | 0.4422827 |
7. Должны ли мы быть уверены в разнице?¶
Похоже, что у нас есть небольшое ухудшение в удержании первого дня, если мы двигаем ворота к сороковому уровню (44.2%) в сравнеии с контрольной группой, где ворота остались на 30-м уровне (44.8%). Разница, конечно, невелика, но даже маленькие изменений в удержании могут иметь значительные последствия. Однако сейчас мы уверены, что различие есть в наблюдаемых данных, а будет ли вариант с воротами на сороковом уровне хуже в будущем?
Есть несколько способов оценки нашей уверенности в наблюдаемых цифрах. Здесь мы попробуем воспользоваться $z$-критерием для проверки гипотезы о равенстве долей, а также бустрапом (bootstrap). Бутсрап подразумевает, что мы будем последовательно ресэмплить с возвращением наш датасет (то есть выбирать случайную подвыборку из всего множества наблюдений) и для каждой выборки считать удержание первого дня. Дисперсия нашего 1-day retention при таком способе вычисления даст нам указание на то, насколько мы должны быть неуверены в оценках нашего удержания.
iterations = 500 # число итераций
boot_1d_30 = rep(0, iterations) # вектор для средних по воротам на 30 уровне
boot_1d_40 = rep(0, iterations) # вектор для средних по воротам на 40 уровне
for(i in 1:iterations){
# генерируем таблицу с повторениями соответствующую по размерам оригинальной
boot_mean = sample_n(df, size = dim(df)[1], replace=TRUE) %>%
group_by(version) %>% summarise(mean = mean(retention_1))
boot_1d_30[i] = boot_mean[1,2]$mean # считаем средние и записываем их в вектора
boot_1d_40[i] = boot_mean[2,2]$mean
}
# строим общую табличку и смотрим на неё
# в колонка таблицы лежат сбутстрапированные распределения для долей вернувшихся в игру с воротами
# на разных уровнях
plot_df = data.frame(gate_30_mean = boot_1d_30, gate_40_mean = boot_1d_40)
head(plot_df)
| gate_30_mean | gate_40_mean |
|---|---|
| 0.4511725 | 0.4379922 |
| 0.4468566 | 0.4392336 |
| 0.4486125 | 0.4418851 |
| 0.4467628 | 0.4461677 |
| 0.4453667 | 0.4446114 |
| 0.4476762 | 0.4437294 |
ggplot(plot_df)+
geom_density(aes(x=gate_30_mean, y=..density.., fill='gate_30'),alpha=0.4) +
geom_density(aes(x=gate_40_mean, y=..density.., fill='gate_40'),alpha=0.4)

8. Смотрим на разницу поближе¶
Эти два распределения представляют собой оценку распределений 1-day retention для наших двух АБ-групп. Даже просто визуально понятно, что какое-то доказательство различия двух групп у нас есть. Посмотрим теперь подробнее на разницу в ретеншене у двух групп.
(Чтобы посчиталось быстрее число итераций мы выбрали достаточно небольшим - всего 500 раз считаем средние по выборкам. В боевых условиях число было бы больше, например, 10 тысяч итераций. )
plot_df['diff'] = (plot_df$gate_30_mean - plot_df$gate_40_mean)/plot_df$gate_40_mean*100
ggplot(plot_df)+
geom_density(aes(x=diff, y=..density.., fill='diff'),alpha=0.4)

9. Вероятность разницы¶

Из этого графика мы видим, что наиболее вероятная разница составляет примерно 1%-2%, а большая часть распределения находится справа от нуля, то есть вариант с воротами на 30 уровне пока выигрывает. Но какова вероятность того, что эта разница больше 0%? Посчитаем и её тоже.
mean(plot_df$diff > 0)
10. 7-day retention по АБ-группам¶
Бутстрап-анализ свидетельствует о высокой вероятности того, что удержание первого дня лучше в группе с воротами на 30-м уровне, чем на 40-м. Однако, так как игроки успели пожить в игре всего один день, вполне возможно, что их большинство еще даже не дошли даже до 30-го уровня. А значит, многие игроки не будут затронуты нашим изменением и сильного эффекта мы не увидим.
Однако спустя неделю после установки, уже больше игроков пройдут 40 уровней, поэтому имеет смысл посмотреть на удержание седьмого дня. Т.е., какой процент людей, установивших игру, снова показался в игре через 7 дней.
Начнем с рассчета 7-day retention для двух АБ-групп.
df %>% group_by(version) %>% summarise(mean(retention_7))
| version | mean(retention_7) |
|---|---|
| gate_30 | 0.1902013 |
| gate_40 | 0.1820000 |
11. Снова бутстрапим разницу¶
Как и с 1-day retention, мы видим, что 7-day retention немного ниже (18.2%), когда ворота находятся на 40-м уровне, чем на 30-м (19.0%). Эта разница также выше, чем для удержания первого дня, скорее всего из-за того, что игроки имели больше времени на то, чтобы столкнуться с первыми воротами. Мы также видим, что удержание 7-го дня в целом ниже, чем удержание 1-го - спустя неделю намного меньше людей всё ещё заходит в игру.
Но как и раньше, давайте применим бутстрап анализ и выясним, насколько уверены мы должны быть в разнице между двумя АБ-группами.
boot_7d_30 = rep(0, iterations)
boot_7d_40 = rep(0, iterations)
for(i in 1:iterations){
boot_mean = sample_n(df, size = dim(df)[1], replace=TRUE)%>% group_by(version) %>% summarise(mean = mean(retention_7))
boot_7d_30[i] = boot_mean[1,2]$mean
boot_7d_40[i] = boot_mean[2,2]$mean
}
plot_df7 = data.frame(gate_30_mean = boot_7d_30, gate_40_mean = boot_7d_40)
head(plot_df7)
| gate_30_mean | gate_40_mean |
|---|---|
| 0.1898322 | 0.1799632 |
| 0.1898799 | 0.1842500 |
| 0.1943012 | 0.1824568 |
| 0.1902426 | 0.1808297 |
| 0.1891226 | 0.1828430 |
| 0.1900943 | 0.1822900 |
plot_df7['diff'] = (plot_df7$gate_30_mean - plot_df7$gate_40_mean)/plot_df7$gate_40_mean*100
ggplot(plot_df7)+
geom_density(aes(x=diff, y=..density.., fill='diff'),alpha=0.4)

mean(plot_df7$diff > 0)
12. Выводы¶
Итак, результаты бутстрапа говорят нам о том, что есть значительное доказательство превышения 7-day retentino в группе с воротами на 30-м уровне над группой с воротами на 40-м. Значит, если мы хотим держать ретеншн на высоком уровне и иметь большее число игроков, нам не нужно сдвигать ворота с 30-го на 40-й уровень.

Так почему же ретеншн выше, когда ворота расположены раньше? Логично было бы ожидать обратной ситуации - чем позже ставится препятствие, тем дольше игроки будут взаимодействовать с игрой. Однако это не то, что мы видим в данных. Теория гедонистической адаптации может помочь с объяснением. Если вкратце, гедонистическая адаптация - это тенденция получать всё меньше и меньше удовольствия от деятельности, если она продолжается длительное время. Заставляя игроков сделать паузу, когда они достигают 30-го уровня, мы продлеваем им удовольствие от игры, в результате чего они хотят в неё возвращаться. И напротив, сдвигая ворота к 40-му уровню мы даем игрокам возможность наиграться и просто заскучать.
13. Z-тест¶
Бутсрап позволил нам посмотреть не просто на какие-то отдельные значения долей, он позволил нам намного большее, сымитировать распределение этих долей. Давайте попробуем воспользоваться здесь z-тестом для равенства долей. Будем проверять гипотезу о том, что 1-day retention с воротами на разных уровнях не отличаются друг от друга против альтернативы, что разичаются. Каких-то априорных мыслей о знаке отличия у нас не возникает, поэтому приходится рассматривать двустороннюю альтернативу.
df_ex = df %>% group_by(version) %>% summarise(m = sum(retention_1),n = n())
df_ex
| version | m | n |
|---|---|---|
| gate_30 | 20034 | 44700 |
| gate_40 | 20119 | 45489 |
test_res = prop.test(x = df_ex$m, n = df_ex$n, correct = FALSE)
test_res
2-sample test for equality of proportions without continuity correction data: df_ex$m out of df_ex$n X-squared = 3.183, df = 1, p-value = 0.07441 alternative hypothesis: two.sided 95 percent confidence interval: -0.0005820999 0.0123924394 sample estimates: prop 1 prop 2 0.4481879 0.4422827
Видим, что гипотеза о равенстве показателей при воротах на разных уровнях не отвергается на $5\%$ уровне значимости. В первый день критерий не может обнаружить различий. Стоит обратить внимание, что в этом примере мы находимся на границе.
df_ex = df %>% group_by(version) %>% summarise(m = sum(retention_7),n = n())
df_ex
| version | m | n |
|---|---|---|
| gate_30 | 8502 | 44700 |
| gate_40 | 8279 | 45489 |
test_res = prop.test(x = df_ex$m, n = df_ex$n, correct = FALSE)
test_res
2-sample test for equality of proportions without continuity correction data: df_ex$m out of df_ex$n X-squared = 10.013, df = 1, p-value = 0.001554 alternative hypothesis: two.sided 95 percent confidence interval: 0.003121044 0.013281552 sample estimates: prop 1 prop 2 0.1902013 0.1820000
На $7$ день различия начинают быть более существенными и гипотеза о равенстве отвергается, причём довольно уверенно отвергается.