MonkeyBench : an interactive environment for library research¶
MonkeyBenchは、Jupyterの上に構築中のライブラリーリサーチのための対話環境です。
ライブラリーリサーチの過程と成果を、そのためのツールの作成と利用込みで、そのまま保存/共有/再利用できるという利点を活かし、調査プロセスの振り返りから質の向上、ノウハウ化を支援する環境となることを目論んでいます。
ノイラートの船ではありませんが、「航海しながら改造し続ける」というコンセプトのため、完成することはありませんが、ツールの寄せ集めという性質上、それぞれ一部分でも利用可能です。
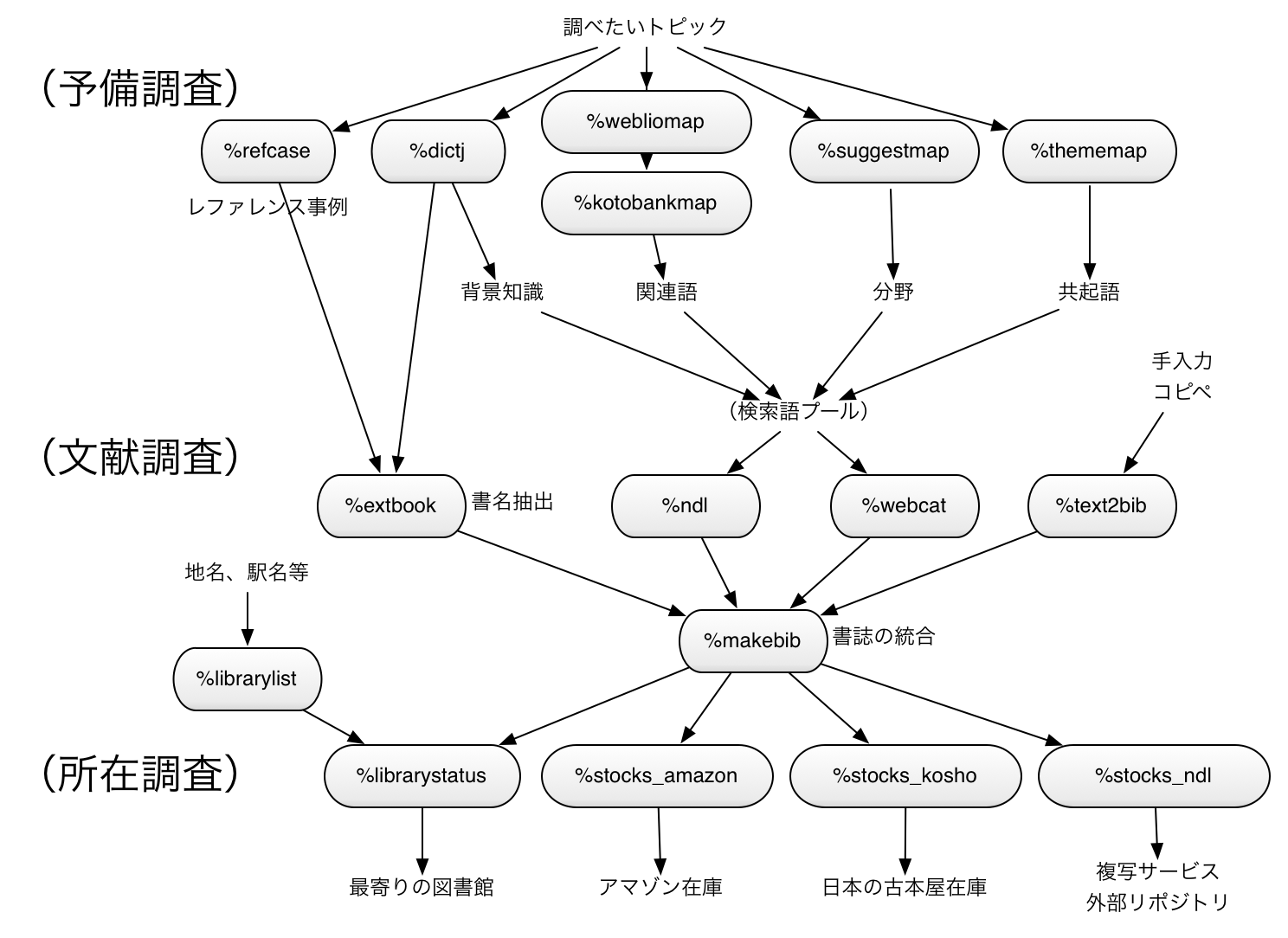
コマンド一覧とワークフロー¶
予備調査¶
| マジックコマンド | 機能 |
|---|---|
| %dictj (キーワード) | キーワードについて手持ちの辞書(EPWING)とネット上の日本語事典をまとめて検索し、記述の短い順から並べて表示 |
| %refcase (キーワード) | レファレンス共同データベースを検索して、レファレンス事例を収集して表示 |
| %thememap (キーワード) | キーワードについてウィキペディアのカテゴリー情報を元に、該当する分野の階層図を作成する |
| %suggestmap (キーワード) | キーワードについてgoogleサジェスト機能を使って、検索で共に使われる共起語を集めてマップ化する |
| %kotobankmap (キーワード) | kotobankの関連キーワードをつかって関連図をつくる |
| %webliomap (キーワード) | weblioの関連キーワードをつかって関連図をつくる |
文献調査¶
| マジックコマンド | 機能 |
|---|---|
| %webcat (キーワード) | webcat plus minusを使って書籍等を検索して、結果をデータフレームにする |
| %ndl (キーワード) | 国会図書館サーチを検索して、結果をデータフレームにする 書籍、雑誌記事だけでなく、デジタル資料やレファレンス事例などを含めて検索できるが、上限500件の制限がある |
| %amazonsimi (キーワード) | アマゾンの類似商品情報を辿って、関連書を集める |
| %amazonmap (キーワード) | アマゾンの類似商品情報を辿って集めた関連書を、関連チャートに図化する |
| %amazonPmap (キーワード) | アマゾンの類似商品情報を辿って集めた関連書を、商品写真を使って関連チャートに図化する |
文献調査補助¶
| マジックコマンド | 機能 |
|---|---|
| %extbook (データフレーム) | データフレーム内に含まれる書名を抜き出してデータフレーム化する 事典検索やレファレンス事例の結果から書名を抜き出すのに用いる |
| %%text2bib (複数行の書誌データ) |
テキストから書誌情報を拾ってデータフレーム化する コピペや手入力で文献を入力するのに用いる |
| %makebib (データフレーム)(データフレーム)…… | 文献調査の各コマンドが出力した複数のデータフレームをマージして重複を除き、詳細情報を取得してデータフレーム化する |
| %amazonreviews (書誌データフレーム) | データフレーム内に含まれる目次情報を展開する |
| %amazonreviews (書誌データフレーム) | データフレーム内に含まれる書籍についてamazonレビューを収集する |
所在調査¶
| マジックコマンド | 機能 |
|---|---|
| %librarylist (地名、駅名など) | 地名、駅名など(コンマ区切りで複数指定可能)を入力すると、該当する/付近の図書館のリストをデータフレームにする 次の%librarystatueで検索対象図書館を指定するのに使う |
| %librarystatue (書誌データフレーム)(図書館リストデータフレーム) | 書誌データフレームと図書館リストデータフレームを受けて、各書籍について各図書館の所蔵/貸出情報/予約用URLを取得してデータフレームする |
| %stock_amazon (書誌データフレーム) | 書誌データフレームを受けて、各書籍についてAmazonの在庫、新刊・中古の最低価格を取得してデータフレームする |
| %stock_kosho (書誌データフレーム) | 書誌データフレームを受けて、各書籍について「日本の古本屋」の在庫、出品店・価格等を取得してデータフレームする |
| %stock_ndl (書誌データフレーム) | 書誌データフレームを受けて、各書籍について国会図書館、各県立図書館の所蔵/貸出情報/予約用URLを取得してデータフレームする |
コード¶
# -*- coding:utf-8 -*-
import urllib2
import requests
import lxml.html
from bs4 import BeautifulSoup
import pandas as pd
from collections import OrderedDict
import re
from IPython.display import HTML
from IPython.core.magic import (register_line_magic, register_cell_magic)
from StringIO import StringIO
import pygraphviz as pgv
import cStringIO
key関係¶
#Amazon アソシエイト Webサービスを利用するためのキー
#Amazonアソシエイトプログラムに参加しトラッキングIDを取得し、
#認証キーとしてAccess Key IDとSecret Access Keyの2つのキーを取得したもの
AMAZON_ASSOC_TAG="xxxxxxxxxxxxx-99"
AMAZON_ACCESS_KEY_ID="XXXXXXXXXXXXXXXXXXXX"
AMAZON_SECRET_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx+x+xxxxx"
#カリールAPI利用のためのキー
calil_app_key = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
汎用ツール系¶
#結果の表示援助
def pp(df, now_index, now_column='description'):
if now_column == 'url':
return HTML(df[now_column][now_index])
else:
return HTML(df[now_column][now_index].replace('\n','<br>'))
def url(df, now_index):
if 'url' in df.columns:
return HTML(df['url'][now_index])
def p(df):
for now_column in df.columns:
print now_column + '\t',
print
print ' --- '
datanum, fieldnum = df.shape
for i in range(0, datanum):
for now_column in df.columns:
print unicode(df[now_column].iat[i]).strip().encode('utf-8')+ '\t',
print
print ' --- '
#データフレームをHTML埋め込み
def embed_df(df):
datanum, fieldnum = df.shape
now_html = '<table><th></th>'
for now_column in df.columns:
now_html += '<th>' +unicode(now_column)+'</th>'
for i in range(0, datanum):
now_html +='<tr><th>{}</th>'.format(i+1)
for now_column in df.columns:
now_item = df[now_column].iat[i]
#print now_item, type(now_item)
if 'url' in now_column and 'http' in unicode(now_item):
now_html += u'<td><a href="{0}" target="_blank">LINK</a></td>'.format(now_item)
else:
now_html += u'<td>' +unicode(now_item) +u'</td>'
now_html +='</tr>'
now_html +='</table>'
return HTML(now_html)
@register_cell_magic
def csv2df(line, cell):
# We create a string buffer containing the
# contents of the cell.
sio = StringIO(cell)
# We use pandas' read_csv function to parse
# the CSV string.
return pd.read_csv(sio)
#『書名』を切り出してリストで返す
def extract_titles_from_text(text, recom):
r = re.compile(recom)
text = unicode(text)
books= r.findall(text)
if books:
return books
else:
return None
def extract_book_titles_from_text(text):
r = re.compile(u'『([^』]+)』')
text = unicode(text)
books= r.findall(text)
if books:
return books
else:
return None
def extract_engbook_titles_from_text(text):
r = re.compile(r'<em>([A-Z][^<]+)</em>')
text = unicode(text)
books= r.findall(text)
if books:
return books
else:
return None
def extract_eng_article_titles_from_text(text):
r = re.compile(u'“([A-Z][^”]+),”')
text = unicode(text)
books= r.findall(text)
if books:
return books
else:
return None
# データフレームから『書名』を抜き出す
def extract_titles_from_df(df, recom):
result_list = []
datanum, fieldnum = df.shape
for i in range( datanum):
for j in range(fieldnum):
title_list = extract_titles_from_text(df.iloc[i,j],recom)
if title_list:
for title in title_list:
if title not in result_list:
result_list.append(title)
return result_list
def ext_book(df):
result_df = pd.DataFrame(columns =['title'])
extract_method = {'本':u'『([^』]+)』','Book':r'<em>([A-Z][^<]+)</em>', 'Article':u'“([A-Z][^”]+),”'}
for category, recom in extract_method.items():
for now_title in extract_titles_from_df(df, recom):
result_dict = OrderedDict()
result_dict['category'] = category,
result_dict['title'] = now_title,
result_df = result_df.append(pd.DataFrame(result_dict))
result_df.index = range(1, len(result_df)+1) #最後にインデックスつけ
return result_df
def ext_amazon(url):
'''
urlで指定されるページからamazon.co.jpへのリンクを抽出してtitle, asinのデータフレームを返す
'''
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding),'lxml')
amazon_items = soup.findAll('a', {'href':re.compile(r'http://www.amazon.co.jp.+')})
result_dict = OrderedDict()
result_dict['title'] = [a.text for a in amazon_items]
result_dict['asin'] = [re.search(r'[0-9X]{10,10}',a.attrs['href']).group() for a in amazon_items]
return pd.DataFrame(result_dict)
Amazon関係¶
from bottlenose import api
from urllib2 import HTTPError
amazon = api.Amazon(AMAZON_ACCESS_KEY_ID, AMAZON_SECRET_KEY, AMAZON_ASSOC_TAG, Region="JP")
def error_handler(err):
ex = err['exception']
if isinstance(ex, HTTPError) and ex.code == 503:
time.sleep(random.expovariate(0.1))
return True
def get_totalpages(keywords, search_index="All"):
response = amazon.ItemSearch(
SearchIndex=search_index,
Keywords=keywords,
ResponseGroup="ItemIds",
ErrorHandler=error_handler)
soup=BeautifulSoup(response, "lxml")
# print soup
totalpages=int(soup.find('totalpages').text)
return totalpages
def item_search(keywords, search_index="All", item_page=1):
try:
response = amazon.ItemSearch(
SearchIndex=search_index,
Keywords=keywords,
ItemPage=item_page,
ResponseGroup="Large",
ErrorHandler=error_handler)
# バイト配列をunicodeの文字列に
# コレをしないと日本語は文字化けします。
u_response = response.decode('utf-8','strict')
soup = BeautifulSoup(u_response, "lxml")
return soup.findAll('item')
except:
return None
def item_title_book_search(title, search_index="Books", item_page=1):
try:
response = amazon.ItemSearch(
SearchIndex=search_index,
Title=title,
ItemPage=item_page,
ResponseGroup="Large",
ErrorHandler=error_handler)
# バイト配列をunicodeの文字列に
# コレをしないと日本語は文字化けします。
u_response = response.decode('utf-8','strict')
soup = BeautifulSoup(u_response, "lxml")
return soup.findAll('item')
except:
return None
文献調査¶
class Searcher(object):
"""
抽象クラス 複数のリソースを始めとする調べて結果を合わせて並べ替えて出力
入力ーキーワード self.keyword
出力ーデータフレーム(項目名、リソース名、内容、記述量など)
クラスプロパティ resource_dict={name : path } リソースのリスト=リソース名とアクセス情報(URLや辞書をのパスなど)
"""
#クラスプロパティ
#リソースのリスト=リソース名とアクセス情報(URLや辞書をのパスなど)
resource_dict={}
def __init__(self, keyword):
self.keyword = keyword
def collector(self):
result_df = pd.DataFrame () #入れ物を用意する
resource_list = self.make_resource_list()
#print len(resource_list), 'Loops'
for resource in resource_list: #リソースリストから一つずつ取り出すループ
print '.',
result_df = result_df.append( self.fetch_data(resource) ) #キーワードについてそのリソースからデータを得て、入れ物に追加
result_df = self.arrange(result_df) #ループ終わったら入れ物の中身をソート
return result_df #入れ物の中身を返す
辞書集め(epwing)¶
import commands
class epwing_info(Searcher):
dict_root = '/Users/kuru/Documents/EPWING/'
resource_dict={
'ブリタニカ小項目版' : ['ブリタニカ国際大百科事典.Windows対応小項目版.2000','-t+'],
'マグローヒル科学技術用語大辞典' : ['マグローヒル科学技術用語大辞典.第3版','-t+'],
'医学大辞典' : ['医歯薬\ 医学大辞典','-t+'],
'岩波日本史辞典' : ['岩波\ 日本史辞典-ebzip','-t+'],
'理化学辞典第五版ebzip' : ['岩波\ 理化学辞典第五版ebzip','-t+'],
'広辞苑' : ['岩波.広辞苑.第六版','-t+'],
'岩波ケンブリッジ世界人名辞典' : ['岩波\=ケンブリッジ世界人名辞典ebzip','-t+'],
'岩波生物学辞典' : ['岩波生物学辞典第四版','-t+'],
'建築事典' : ['建築事典ebzip','-t+'],
'リーダーズ' : ['研究社\ リーダーズプラス\ V2ebzip','-t+'],
'大辞林' : ['三省堂大辞林','-t+'],
'参考図書2.4万冊' : ['参考図書2.4万冊','-t+'],
'参考調査便覧' : ['参考調査便覧epwing','-tmax'],
'国語大辞典' : ['小学館\ 国語大辞典ebzip','-t+'],
'日本大百科全書' : ['小学館\ 日本大百科全書ebzip','-t+'],
'ランダムハウス英語辞典' : ['小学館.ランダムハウス英語辞典','-t+'],
'大辞泉' : ['小学館.大辞泉','-t+'],
'心理学用語辞典' : ['心理学用語辞典','-t+'],
'人物レファレンス事典' : ['人物レファレンス事典\ 日本編-ebzip','-t+'],
'南山堂医学大辞典' : ['南山堂医学大辞典第18版','-t+'],
'科学技術45万語対訳辞典' : ['日外アソシエーツ\ 科学技術45万語対訳辞典\ 英和/和英','-t+'],
'物語要素事典' : ['物語要素事典epwing','-t+'],
'世界大百科事典' : ['平凡社\ 世界大百科事典\ 第二版','-t+'],
'有斐閣経済辞典' : ['有斐閣-経済辞典-第3版-ebzip','-t+']}
def make_resource_list(self):
return self.resource_dict.keys()
def make_query(self, resource_name):
dict_info = self.resource_dict[resource_name]
path = self.dict_root + dict_info[0]
search_mode = dict_info[1]
return 'ebmini -b{dict_path} -KIu -KOu -n1 {mode} -l- -s{keyword}'.format(dict_path=path, mode=search_mode, keyword=self.keyword)
def fetch_data(self, resource_name):
result = commands.getoutput(self.make_query(resource_name) )
result_dict = OrderedDict()
result_dict['item_title'] = result.split('\n')[0].decode('utf-8'),
result_dict['dict_name'] = resource_name.decode('utf-8'),
result_dict['description'] = result.decode('utf-8'),
result_dict['des_size'] = len(result),
return pd.DataFrame(result_dict)
def arrange(self, df):
if not df.empty:
df = df[df.des_size >0] #長さゼロは抜く
df = df[df.item_title !='Error: eb_bind() failed.'] #失敗は抜く
df = df.sort_values(by='des_size') #並べ替え
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
コトバンク¶
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'}
class Kotobank_info(Searcher):
def make_resource_list(self):
'''
yahoo辞書でキーワードを拾い直して、それらのキーワードそれぞれにURLを作って、リストで返す
'''
url = 'http://dic.search.yahoo.co.jp/search?p=' + self.keyword + '&stype=exact&aq=-1&oq=&ei=UTF-8'
content = requests.get(url, headers=headers).text
soup = BeautifulSoup(content, "lxml")
#<h3><a href="・・・・">駄洒落</a></h3>
url_list = []
h3_soups = soup.findAll('h3')
if h3_soups:
for h3_soup in h3_soups:
url = 'https://kotobank.jp/word/' + urllib2.quote(h3_soup.text.encode('utf-8'))
if url not in url_list:
url_list.append(url)
return url_list
def fetch_data(self, url):
'''
URLを開いてパースして拾い出す
'''
content = requests.get(url, headers=headers).text
soup = BeautifulSoup(content, "lxml")
article_soups = soup.findAll('article')
result_df = pd.DataFrame()
if article_soups:
#ダイレクトで見つかった場合
for article_soup in article_soups:
# <h2>◯◯辞典<span>の解説</span></h2>を見つけて
dict_name = article_soup.find('h2').text
dict_name = dict_name.replace(u'の解説','')
# <h3>項目/h3>を見つけて
item_title_soup = article_soup.find('h3')
item_title = item_title_soup.text.replace('\n','').strip()
# <section class=description>を見つけて
description_soup = article_soup.find('section', class_='description')
description = description_soup.text
description = description.replace('\t','').strip()
description = description.replace('\n','').strip()
description = description.replace(' ','').strip()
result_dict = OrderedDict()
result_dict['item_title'] = item_title,
result_dict['dict_name'] = dict_name,
result_dict['description'] = description,
result_dict['des_size'] = len(description),
result_dict['url'] = url,
newdf = pd.DataFrame(result_dict)
result_df = result_df.append(newdf)
return result_df
else:
return None
def arrange(self, df):
#print df
if not df.empty:
df = df[df.des_size >0] #長さゼロは抜く
df = df.sort_values(by='des_size') #並べ替え
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
Weblio¶
def weblio(keyword):
#keyword = 'ニューラルネットワーク'
url = 'http://www.weblio.jp/content/'+keyword
r = requests.get( url)
tree = lxml.html.fromstring(r.content)
# links = tree.xpath('//div[@class="pbarTL"]') #辞書名
#links = tree.xpath('//div[@class="NetDicHead"]') #項目名のタグは辞書ごとに違うみたい
# links = tree.xpath('//h2[@class="midashigo"]' )#各辞書の見出し
# links = tree.xpath('//div[@class="sideRWordsL"]/a') #関連語
links = tree.xpath('//*[@id="topicWrp"]/span' ) #全体の見出し
for link in links:
print link.text_content()
print link.attrib['href']
Encyclopedia.com¶
def myjoin(list):
result = ''
for i in list:
result += unicode(i)
return result
class encyclopediacom_info(Searcher):
def make_resource_list(self):
url = 'http://www.encyclopedia.com/searchresults.aspx?q=' + self.keyword
content = requests.get(url, headers=headers).text
soup = BeautifulSoup(content, "lxml")
#<a class="maltlink" href="/topic/encyclopedia.aspx" onclick="OmnitureClick('SearchResults20008.topiclink');">encyclopedia</a>
maltlink_soup = soup.find('a', class_='maltlink')
if maltlink_soup:
url_list = 'http://www.encyclopedia.com' + dict(maltlink_soup.attrs)['href'],
return url_list
def fetch_data(self, url):
'''
URLを開いてパースして拾い出す
'''
# driver = webdriver.PhantomJS()
# driver.get(url)
# r = driver.page_source
r = requests.get(url)
soup = BeautifulSoup(r.text,"lxml")
article_titles = soup.findAll('h2', class_ ='doctitle')
source_titles = soup.findAll('span', class_='pub-name')
be_doc_texts = soup.findAll('div', id='be-doc-text')
APA_citations = soup.findAll('div', id='divAPA')
df = pd.DataFrame()
for article_title, source_title, doc_text, apa in zip(article_titles, source_titles, be_doc_texts, APA_citations):
result_dict = OrderedDict()
result_dict['item_title'] = article_title.text,
result_dict['dict_name'] = source_title.text,
#result_dict['description'] = doc_text.text,
result_dict['description'] = myjoin(doc_text.contents),
#result_dict['citation'] = apa.find('p', class_='cittext').text,
result_dict['citation'] = myjoin(apa.find('p', class_='cittext')),
result_dict['des_size'] = len(doc_text.text),
df = df.append(pd.DataFrame(result_dict))
return df
def arrange(self, df):
if not df.empty:
df = df[df.des_size >0] #長さゼロは抜く
df = df.sort_values(by='des_size') #並べ替え
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
Wikipedias¶
class Wikipedia_Info(object):
def __init__(self, keyword, language='en'):
self.keyword = keyword
self.language = language
def fetch_page(self):
import wikipedia
wikipedia.set_lang(self.language)
language_dict = wikipedia.languages()
try:
page = wikipedia.WikipediaPage(self.keyword)
result_dict = OrderedDict()
result_dict['item_title'] = unicode(page.original_title),
result_dict['dict_name'] = u'Wikipedia ' + language_dict[self.language],
result_dict['description'] = page.content,
result_dict['des_size'] = len(page.content),
result_dict['url'] = page.url,
wiki_df = pd.DataFrame(result_dict)
return wiki_df
except:
print u'Page {} does not match any pages in {} '.format(self.keyword, u'Wikipedia ' + language_dict[self.language])
def interlanguage(keyword):
url = "https://ja.wikipedia.org/wiki/" + keyword
print url
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
result_dict = OrderedDict()
# <li class="interlanguage-link interwiki-ab">
# <a href="//ab.wikipedia.org/wiki/%D0%90%D0%BB%D0%B0" title="アブハズ語: Ала" lang="ab" hreflang="ab">Аҧсшәа</a>
# </li>
interlanguage_link_soups = soup.findAll("li", class_=re.compile(r'interlanguage.+'))
#print interlanguage_link_soups
if interlanguage_link_soups:
result_dict['word'] = [dict(l.a.attrs)['title'].split(': ')[1] for l in interlanguage_link_soups]
result_dict['language'] = [dict(l.a.attrs)['title'].split(': ')[0] for l in interlanguage_link_soups]
result_dict['lang'] = [l.text for l in interlanguage_link_soups]
result_dict['url'] = ['https:' +dict(l.a.attrs)['href'] for l in interlanguage_link_soups]
df = pd.DataFrame(result_dict)
return df[df['lang'].str.contains(u'English|Français|Deutsch|EspañolItaliano|Esperanto|Русский|العربية|Latina|Ελληνικά|中文|فارسی|संस्कृतम्')]
Wikitionaries¶
def wikitionary(keyword):
#title = 'dog'
url = 'http://en.wiktionary.org/w/api.php?format=xml&action=query&prop=revisions&titles={}&rvprop=content'.format(title)
r = requests.get(url)
print r.text
図書館関係¶
import requests
from bs4 import BeautifulSoup
import re
class library_info_list(Searcher):
default_max_page = 20
def __init__(self, keyword, max_page = default_max_page):
self.keyword = keyword
self.max_onepage = max_page
def get_hit_num(self, firstpage = 0):
url = self.get_query(firstpage, max_page = 1)
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding), "lxml")
hit_num_result = self.parse_hit_num(soup)
if hit_num_result:
return int(hit_num_result.group(1))
else:
return 0
def make_resource_list(self):
last_page = self.get_hit_num()
return [self.get_query(page, max_page = self.max_onepage) for page in range (0, last_page, self.max_onepage)]
def fetch_data(self, url):
result_df = pd.DataFrame()
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding), "lxml")
for item_soup in self.get_item_soup(soup):
result_dict = self.parse_data(item_soup)
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
def arrange(self, df):
if not df.empty:
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
国会図書館サーチ¶
class ndl_list_info(Searcher):
def get_query(self):
print 'http://iss.ndl.go.jp/api/opensearch?any={}'.format(self.keyword.encode('utf-8'))
return 'http://iss.ndl.go.jp/api/opensearch?any={}&cnt=500'.format(self.keyword.encode('utf-8'))
def fetch_data(self, soup):
#基本項目
basic_tag_list =['category','guid','dc:title','dcndl:titletranscription',
'dc:creator','dcndl:edition','dc:publisher','dcterms:issued','dc:subject']
#print soup
result_dict = OrderedDict()
for tag in basic_tag_list:
tag_soup = soup.find(tag)
if tag_soup:
result_dict[tag] = tag_soup.text.strip(),
else:
result_dict[tag] = '',
#identifier
identifier_type_list = ['dcndl:ISBN', 'dcndl:JPNO']
for tag in identifier_type_list:
tag_content = soup.find('dc:identifier', {'xsi:type' : tag})
if tag_content:
result_dict[tag] = tag_content.text.strip(),
else:
result_dict[tag] = '',
#seeAlso
result_dict['ndldc_url'] = result_dict['ndlopac_url'] = result_dict['jairo_url'] = result_dict['cinii_url'] = '',
for also_soup in soup.findAll('rdfs:seealso'):
resource_url = dict(also_soup.attrs)['rdf:resource']
if r'http://dl.ndl.go.jp' in resource_url:
result_dict['ndldc_url'] = resource_url, #デジタルコレクション
elif r'http://id.ndl.go.jp/bib' in resource_url:
result_dict['ndlopac_url'] = resource_url, #NDL−OPAC詳細、複写依頼も
elif r'http://jairo.nii.ac.jp' in resource_url:
result_dict['jairo_url'] = resource_url, #JAIRO
elif r'http://ci.nii.ac.jp' in resource_url:
result_dict['cinii_url'] = resource_url, #CiNii
return pd.DataFrame(result_dict)
def make_resource_list(self):
url = self.get_query()
r = requests.get(url)
soup = BeautifulSoup(r.content, "lxml")
return soup.findAll("item")
def arrange(self, df):
if not df.empty:
df.columns = ['category','ndl_url','title','titletranscription','creator',
'edition','publisher','issued','subject','isbn','jpno',
'ndldc_url','ndlopac_url','jairo_url','cinii_url']
df = df.sort_values(by='category')
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
CiNii Article¶
class CiNii_list_info(library_info_list):
default_max_page = 200
#http://ci.nii.ac.jp/search?q=%E6%96%87%E5%8C%96%E7%A5%AD&range=0&sortorder=1&count=200&start=201
def get_query(self, page, max_page):
return 'http://ci.nii.ac.jp/search?' + \
'q=' + self.keyword + \
'&&range=0&sortorder=1&count=' + str(max_page) + '&start=' + str(page)
def make_resource_list(self):
last_page = self.get_hit_num()
return [self.get_query(page, max_page = self.max_onepage) for page in range (1, last_page, self.max_onepage)]
#特異
def parse_hit_num(self, soup):
#<h1 class="heading"?
# <span class="hitNumLabel">検索結果</span>
#
# 407件中 1-200 を表示
hit_soup = soup.find("h1", class_="heading")
recom = re.compile(u'([0-9]+)件中')
return recom.search(hit_soup.text)
def get_item_soup(self, soup):
return soup.findAll("dl", class_="paper_class")
def get_detail_title(self, soup):
return soup.find("dt", class_="item_mainTitle item_title").text.strip()
# <p class="item_subData item_authordata">
def get_detail_author(self, soup):
return soup.find("p", class_="item_subData item_authordata").text.replace('\n','').replace('\t','').strip()
def get_detail_journaldata(self, soup):
return soup.find("span", class_="journal_title").text.strip()
def get_detail_url(self, soup):
title_soup = soup.find("dt", class_="item_mainTitle item_title")
return 'http://ci.nii.ac.jp' + dict(title_soup.a.attrs)['href']
# <p class="item_otherdata">
def get_otherdata_url(self, soup):
title_soup = soup.find("p", class_="item_otherdata")
if title_soup.a:
return 'http://ci.nii.ac.jp' + dict(title_soup.a.attrs)['href']
else:
return ''
def parse_data(self, soup):
result_dict = OrderedDict()
result_dict['title'] = self.get_detail_title(soup),
result_dict['author'] = self.get_detail_author(soup),
result_dict['journal'] = self.get_detail_journaldata(soup),
result_dict['url'] = self.get_detail_url(soup),
result_dict['ext_url'] = self.get_otherdata_url(soup),
return result_dict
Webcat Plus Minus¶
class webcat_list_info(library_info_list):
default_max_page = 300
def get_query(self, page, max_page):
return 'http://webcatplus.nii.ac.jp/pro/?' + \
'q=' + self.keyword + \
'&n=' + str(max_page) + '&o=yd&lang=ja&s=' + str(page)
def parse_hit_num(self, soup):
# <div id="hit">検索結果 803件中
hit_soup = soup.find("div", id="hit")
recom = re.compile(r'検索結果 ([0-9]+)件中')
return recom.search(hit_soup.string.encode('utf-8'))
def fetch_data(self, url):
result_df = pd.DataFrame()
r = requests.get(url)
tree = lxml.html.fromstring(r.content)
titles = tree.xpath('//*[@id="docs"]/ol/li/div/a')
descris = tree.xpath('//*[@id="docs"]/ol/li/div[2]')
for title,descri in zip(titles, descris):
#print link.text,link.attrib['href'],descri.text
result_dict = OrderedDict()
result_dict['title'] = title.text,
result_dict['description'] = descri.text,
result_dict['url'] = 'http://webcatplus.nii.ac.jp/' + title.attrib['href'],
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
class webcat_list_info_old(library_info_list):
default_max_page = 300
#特異
def get_query(self, page, max_page):
return 'http://webcatplus.nii.ac.jp/pro/?' + \
'q=' + self.keyword + \
'&n=' + str(max_page) + '&o=yd&lang=ja&s=' + str(page)
#特異
def parse_hit_num(self, soup):
# <div id="hit">検索結果 803件中
hit_soup = soup.find("div", id="hit")
recom = re.compile(r'検索結果 ([0-9]+)件中')
return recom.search(hit_soup.string.encode('utf-8'))
#<li class="doc">
#<div class="t"><a href="/webcatplus/details/book/30016474.html" target="webcatplus">深層学習</a></div>
#<div class="d">岡谷貴之 著, 講談社, 2015.4, 165p, <span class="st">機械学習プロフェッショナルシリーズ / 杉山将 編</span> </div>
#</li>
#特異
def get_item_soup(self, soup):
return soup.findAll("li", class_="doc")
#特異
def get_detail_title(self, soup):
return soup.find("div", class_="t").text
#特異
def get_detail_biblio(self, soup):
return soup.find("div", class_="d").text
#特異
def get_detail_url(self, soup):
title_soup = soup.find("div", class_="t")
return 'http://webcatplus.nii.ac.jp' + dict(title_soup.a.attrs)['href']
#特異
def parse_data(self, soup):
result_dict = OrderedDict()
result_dict['title'] = self.get_detail_title(soup),
result_dict['description'] = self.get_detail_biblio(soup),
result_dict['url'] = self.get_detail_url(soup),
return result_dict
class webcat_list_info_title(webcat_list_info):
def get_query(self, page, max_page):
return 'http://webcatplus.nii.ac.jp/pro/?' + \
't=' + self.keyword + \
'&n=' + str(max_page) + '&o=yd&lang=ja&s=' + str(page)
class title2webcat_list(Searcher):
def __init__(self, list):
self.list = list
def make_resource_list(self):
return self.list
def fetch_data(self, title):
w = webcat_list_info_title(title)
return w.collector()
def arrange(self, df):
if not df.empty:
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
class webcat_info(Searcher):
def __init__(self, keyword):
self.keyword = keyword
def make_resource_list(self):
wl = webcat_list_info(self.keyword)
return list(wl.collector()['url'])
def howmany(self):
return len(self.make_resource_list())
def fetch_data(self, url):
result_df = pd.DataFrame(columns=['isbn','ncid','nbn','title','author','publisher','issued',
'pages','summary','contents'])
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding), "lxml")
# ISBN
isbn_soup = soup.find('th', text="ISBN")
if isbn_soup:
result_df['isbn'] = isbn_soup.next_sibling.next_sibling.text.strip(),
else:
result_df['isbn'] = '',
# NII書誌ID(NCID)
ncid_soup = soup.find('span', class_="ncid")
if ncid_soup:
result_df['ncid'] = ncid_soup.string,
else:
result_df['ncid'] = '',
# 全国書誌番号(JP番号)
nbn_soup = soup.find('span', class_="nbn")
if nbn_soup:
result_df['nbn'] = nbn_soup.string,
else:
result_df['nbn'] = '',
title = ''
title_soup = soup.find("h2", id="jsid-detailTabTitle")
if title_soup:
title = re.sub(r'[\s]+', " ", title_soup.text)
else:
title = ''
seriestitle_soup = soup.find('th', text="シリーズ名")
if seriestitle_soup:
seriestitle = re.sub(r'[\s]+', " ", seriestitle_soup.next_sibling.next_sibling.text)
title += ' ' + seriestitle
result_df['title'] = title,
author_soup = soup.find("p", class_="p-C")
if author_soup:
result_df['author'] = author_soup.string,
else:
result_df['author'] = '',
publisher_soup = soup.find('th', text="出版元")
if publisher_soup:
result_df['publisher'] = publisher_soup.next_sibling.next_element.next_element.strip(),
else:
result_df['publisher'] = '',
year_soup = soup.find('th', text="刊行年月")
if year_soup:
result_df['issued'] = year_soup.next_sibling.next_sibling.string,
else:
result_df['issued'] = '',
page_soup = soup.find('th', text="ページ数")
if page_soup:
result_df['pages'] = page_soup.next_sibling.next_sibling.text.strip(),
else:
result_df['pages'] = '',
#概要
summary_soup = soup.find("div", id="jsid-detailMainText").find("p", class_="p-A")
if summary_soup:
result_df['summary'] = summary_soup.string,
else:
result_df['summary'] = '',
#目次
contents = ''
mokuji_ul = soup.find("ul", class_="ul-A")
if mokuji_ul:
mokuji_list_soup = mokuji_ul.findAll("li")
for mokuji_item_soup in mokuji_list_soup:
contents += mokuji_item_soup.string + '\t'
#掲載作品
mokuji_div = soup.find("div", class_="table-A")
if mokuji_div:
mokuji_list_soup = mokuji_div.findAll("tr")
for mokuji_item_soup in mokuji_list_soup:
title_and_author = mokuji_item_soup.text
title_and_author = re.sub(r'\n[\n\s]+',' - ', title_and_author)
# print title_and_author.encode('utf-8')
title_and_author = title_and_author.replace('\n','')
contents += title_and_author + '\t'
contents = contents.replace(u'著作名著作者名\t','')
result_df['contents'] = contents,
#削ったら 2/5の時間で済んだ
# 1 loops, best of 3: 24.8 s per loop
# 1 loops, best of 3: 10.2 s per loop
#NDC,NDCL,値段をNDLへ見に行く
# result_df['ndc'] = ''
# result_df['ndlc'] = ''
# result_df['price'] = ''
# result_df['ndl_url'] = ''
# # "http://iss.ndl.go.jp/books/R100000002-I025967743-00.json"
# ndl_re = re.compile(r'(http://iss.ndl.go.jp/books/[0-9RI\-]+)')
# ndl_result = ndl_re.search(r.text)
# if ndl_result:
# try:
# ndl_url = ndl_result.group(0)
# ndl_json_url = ndl_url + '.json'
# ndl_r = requests.get(ndl_json_url)
# ndl_json = ndl_r.json()
# # print ndl_json
# #分類
# if u'subject' in ndl_json:
# subject = ndl_json[u'subject']
# if u'NDC8' in subject:
# result_df['ndc'] = subject[u'NDC8'][0],
# elif u'NDC9' in subject:
# result_df['ndc'] = subject[u'NDC9'][0],
# if u'NDLC' in subject:
# result_df['ndlc'] = subject[u'NDLC'][0],
# #価格
# if u'price' in ndl_json:
# result_df['price'] = ndl_json[u'price'],
# result_df['ndl_url'] = ndl_url
# except:
# print "can't get: " + ndl_url
return result_df
def arrange(self, df):
if not df.empty:
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
WorldCat¶
class Worldcat_list_info(library_info_list):
default_max_page = 10
#特異
def get_query(self, page, max_page):
return 'http://webcatplus.nii.ac.jp/pro/?' + \
'q=' + self.keyword + \
'&n=' + str(max_page) + '&o=yd&lang=ja&s=' + str(page)
#特異
def parse_hit_num(self, soup):
# <div id="hit">検索結果 803件中
hit_soup = soup.find("div", id="hit")
recom = re.compile(r'検索結果 ([0-9]+)件中')
return recom.search(hit_soup.string.encode('utf-8'))
def fetch_data(self, url):
result_df = pd.DataFrame()
r = requests.get(url)
tree = lxml.html.fromstring(r.content)
titles = tree.xpath('//*[@id="docs"]/ol/li/div/a')
descris = tree.xpath('//*[@id="docs"]/ol/li/div[2]')
for title,descri in zip(titles, descris):
#print link.text,link.attrib['href'],descri.text
result_dict = OrderedDict()
result_dict['title'] = title.text,
result_dict['description'] = descri.text,
result_dict['url'] = 'http://webcatplus.nii.ac.jp/' + title.attrib['href'],
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
レファレンス共同データベース¶
import urllib2
class refcases_list_info(library_info_list):
default_max_page = 200
def make_resource_list(self):
last_page = self.get_hit_num() / self.max_onepage + 1
return [self.get_query(page, max_page = self.max_onepage) for page in range (1, last_page + 1)]
def get_query(self, page, max_page):
query = 'http://crd.ndl.go.jp/reference/modules/d3ndlcrdsearch/index.php?page=detail_list&type=reference'
query += '&mcmd=' + str(max_page) + '&st=score&asc=desc&kg1=99'
query += '&kw1=' + urllib2.quote(self.keyword.encode('utf-8')) + '&kw_lk1=1&kg2=2&kw2=&kw_lk2=1&kg3=6&pg=' + str(page)
return query
def parse_hit_num(self, soup):
hit_soup = soup.find("div", id="TabbedPanels1")
recom = re.compile(u'検索結果 ([0-9]+)件中')
return recom.search(soup.text)
def get_hit_num(self):
url = self.get_query(page = 1, max_page = 10)
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding), "lxml")
hit_num_result = self.parse_hit_num(soup)
if hit_num_result:
return int(hit_num_result.group(1))
else:
return 0
def get_item_soup(self, soup):
table_soup = soup.find('table', class_='slTable')
return table_soup.findAll('a', {'href':re.compile(r'http://crd.ndl.go.jp/reference/modules/d3ndlcrdentry/index.php?.+')})
def get_detail_title(self, soup):
return soup.text
def get_detail_url(self, soup):
return dict(soup.attrs)['href']
def parse_data(self, soup):
result_dict = OrderedDict()
result_dict['title'] = self.get_detail_title(soup),
result_dict['detail_url'] = self.get_detail_url(soup),
return result_dict
class Refcases_info(Searcher):
def __init__(self, keyword, search_num):
self.keyword = keyword
self.search_num = search_num
def make_resource_list(self):
rl = refcases_list_info(self.keyword)
return list(rl.collector()['detail_url'])[:self.search_num]
def howmany(self):
return len(self.make_resource_list())
def fetch_data(self, url):
result_dict = OrderedDict()
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding), "lxml")
#<div class="refCaseBox">
refcases_soup = soup.find('table', class_="refCaseTable")
th_soups = refcases_soup.findAll('th')
td_soups = refcases_soup.findAll('td')
for th_soup, td_soup in zip(th_soups, td_soups):
result_dict[th_soup.text] = th_soup.next_sibling.text,
result_dict['url'] = url
return pd.DataFrame(result_dict)
def arrange(self, df):
if not df.empty:
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
複数のブックリストを束ねて詳細を得る¶
class list2webcat_info(webcat_info):
def __init__(self, url_list):
self.url_list = url_list
def make_resource_list(self):
return self.url_list
def nbn2webcaturl(nbn):
return 'http://webcatplus.nii.ac.jp/webcatplus/details/book/nbn/{}.html'.format(nbn)
def ncid2webcaturl(ncid):
return 'http://webcatplus.nii.ac.jp/webcatplus/details/book/ncid/{}.html'.format(ncid)
def isbn2webcaturl(isbn):
url = 'http://webcatplus.nii.ac.jp/pro/?i=' + isbn
content = requests.get(url).text
soup = BeautifulSoup(content, "lxml")
title_soup = soup.find('li', class_='doc')
if title_soup:
return 'http://webcatplus.nii.ac.jp' + dict(title_soup.find('div', class_='t').a.attrs)['href']
else:
return None
def title2webcaturl(title):
url = 'http://webcatplus.nii.ac.jp/pro/?t=' + title
content = requests.get(url).text
soup = BeautifulSoup(content, "lxml")
title_soup = soup.find('li', class_='doc')
if title_soup:
return 'http://webcatplus.nii.ac.jp' + dict(title_soup.find('div', class_='t').a.attrs)['href']
else:
return None
def asin2webcaturl(asin):
if asin[0].isdigit():
#そのままISBNとしてurlをつくる
return isbn2webcaturl(asin)
else:
#Amazonでタイトル取得
items = item_search(asin)
title = items[0].find('title').text
return title2webcaturl (title)
def df2webcaturl(df):
if 'url' in df.columns and 'http://webcatplus.nii.ac.jp' in df['url'].iat[0]:
return [url for url in df['url']]
elif 'isbn' in df.columns:
return [isbn2webcaturl(isbn) for isbn in df['isbn']]
elif 'asin' in df.columns:
return [asin2webcaturl(asin) for asin in df['asin']]
elif 'title' in df.columns:
return [title2webcaturl(title) for title in df['title']]
def df_list2webcaturl(df_list):
'''
ブックリスト系のデータフレームを複数受けて、重複を除いてwebcat詳細ページのurlリストを返す
'''
urls =[]
for df in df_list:
#print type(df)
for url in df2webcaturl(df):
if url and not url in urls:
urls.append(url)
return urls
def make_biblio(df_list):
urls = df_list2webcaturl(df_list)
#print urls
w = list2webcat_info(urls)
return w.collector()
def keyword2webcaturl(keyword):
url = 'http://webcatplus.nii.ac.jp/pro/?m=b&q=' + keyword
content = requests.get(url).text
soup = BeautifulSoup(content, "lxml")
title_soup = soup.find('li', class_='doc')
if title_soup:
#タイトルとurlのリストを返す
return [title_soup.find('div', class_='t').text, 'http://webcatplus.nii.ac.jp' + dict(title_soup.find('div', class_='t').a.attrs)['href'] ]
else:
return None
def textlist2webcaturl(text):
'''
text2bib関数の補助というか中身
'''
df = pd.DataFrame(columns=['description','url'])
for line in text.split('\n'):
#print 'this book is being searched ' + line
line = re.sub(u'[『』、,]', ' ', line)
splited_line = line.split()
#見つかるまで少しずつキーワードを縮めていく(最低2個)
for i in range(len(splited_line),1,-1):
keyword = '+'.join(splited_line[0:i])
#print keyword
now_result = keyword2webcaturl(keyword)
if now_result:
#print 'hit ' +now_result[0] + now_result[1]
df = df.append(pd.DataFrame({'description':[line],'url':[now_result[1]]}))
break
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
@register_cell_magic
def text2bib(line, cell):
'''
テキスト形式の書誌情報からwebcat pro詳細ページのurlを取得して書誌データフレームに統合できる形式で返す
返り値:DataFrame
書式:
%%text2bib
(書誌情報1:タイトル 著者名 など;スペースなどで区切る。次項目とは改行区切り)
(書誌情報2:タイトル 著者名 など;スペースなどで区切る。次項目とは改行区切り)
……
例:
%%text2bib
フランクリン R.バーリンゲーム 中村保男訳. 時事通信社, 1956.
フランクリン研究 その経済思想を中心として 久保芳和 関書院, 1957.
フランクリンとアメリカ文学 渡辺利雄 研究社出版, 1980.4. 研究社選書
進歩がまだ希望であった頃 フランクリンと福沢諭吉 平川祐弘 新潮社, 1984.9. のち講談社学術文庫
フランクリン 板倉聖宣 仮説社, 1996.8. やまねこ文庫
ベンジャミン・フランクリン、アメリカ人になる ゴードン・S・ウッド 池田年穂,金井光太朗,肥後本芳男訳. 慶應義塾大学出版会
'''
sio = StringIO(cell)
return textlist2webcaturl(sio.getvalue())
Amazon Review¶
def isbn13to10(isbn):
#978-4-532-35628-6
isbn = isbn.replace('-','')
a = re.search(r'978([0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9])[0-9]', str(isbn))
if a:
isbn9 = a.group(1).replace('-','')
#print isbn9
list_ismb9 = list(str(isbn9))
#print list_ismb9
list_ismb9.reverse()
sum = 0
w = 2
for i in list_ismb9:
sum += int(i) * w
w += 1
d = 11 - (sum % 11)
if d == 11:
d = '0'
elif d == 10:
d = 'x'
else:
d = str(d)
return isbn9 + d
else:
return isbn
def get_review_url(ASIN):
return 'http://www.amazon.co.jp/product-reviews/' + \
str(ASIN) + '/ref=cm_cr_dp_see_all_summary?ie=UTF8&showViewpoints=1&sortBy=byRankDescending'
# def get_review_url2(ASIN):
# return 'http://www.amazon.co.jp/product-reviews/' + \
# str(ASIN) + '/ref=cm_cr_dp_see_all_summary?ie=UTF8&pageNumber=2&sortBy=byRankDescending'
# <span class="a-size-medium a-text-beside-button totalReviewCount">18</span>
def fetch_review(url):
r = requests.get(url)
if r.status_code == 200:
# soup = BeautifulSoup(r.text.encode(r.encoding), "html.parser")
soup = BeautifulSoup(r.text.encode('utf-8'), "lxml")
#<span class="a-size-base review-text">レビュー</span>
review_title_list = soup.findAll("a", class_="a-size-base a-link-normal review-title a-color-base a-text-bold")
review_list = soup.findAll("span", class_="a-size-base review-text")
review_buffer =''
for review_title, review_item in zip(review_title_list, review_list):
review_buffer += u'◯' +review_title.text +u':'+ review_item.text+'\t'
return review_buffer
def amazon_review(ISBN):
return fetch_review(get_review_url(isbn13to10(ISBN)))
class amazon_reviews(Searcher):
def __init__(self, df):
self.biblio_df = df
def make_resource_list(self):
if 'isbn' in self.biblio_df.columns:
return list(self.biblio_df['isbn'])
elif 'asin' in self.biblio_df.columns:
return list(self.biblio_df['asin'])
else:
return None
def fetch_data(self, isbn):
result_df = pd.DataFrame()
if isbn:
url = get_review_url(isbn13to10(isbn))
r = requests.get(url)
if r.status_code == 200:
soup = BeautifulSoup(r.text.encode('utf-8'), "lxml")
review_book = soup.find('a',class_="a-size-large a-link-normal")
review_title_list = soup.findAll("a", class_="a-size-base a-link-normal review-title a-color-base a-text-bold")
review_list = soup.findAll("span", class_="a-size-base review-text")
for review_title, review_item in zip(review_title_list, review_list):
result_dict = OrderedDict()
result_dict['isbn'] = isbn,
result_dict['book_title'] = review_book.text,
result_dict['review_title'] = review_title.text,
result_dict['description'] = review_item.text,
result_dict['des_size'] = len(review_item.text),
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
def arrange(self, df):
if not df.empty:
df.sort_values(by='book_title')
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
所在情報¶
カリール¶
liblary_columns=['systemid','systemname','formal','address','tel','geocode','category','url_pc']
def near_libraries_df(locate):
'''
地名を渡して付近の図書館のリスト(館名、住所、電話、geocode、URLなど)のデータフレームを返す
'''
df = pd.DataFrame(columns=liblary_columns)
#print locate
geocoding_url = 'http://www.geocoding.jp/api/?v=1.1&q={}'.format(locate.encode('utf-8'))
r = requests.get(geocoding_url)
soup = BeautifulSoup(r.text.encode(r.encoding),"lxml")
#print soup
lng = soup.find('lng').text
lat = soup.find('lat').text
url = 'http://api.calil.jp/library?appkey={}&geocode={},{}'.format(calil_app_key, lng, lat)
r = requests.get(url)
soup = BeautifulSoup(r.text.encode(r.encoding),"lxml")
libraries = soup.findAll('library')
for library_soup in libraries:
now_dict = OrderedDict()
for now_column in liblary_columns:
now_dict[now_column] = [library_soup.find(now_column).text]
df = df.append(pd.DataFrame(now_dict))
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
def prefecture_libraries_df(locate):
df = pd.DataFrame(columns=liblary_columns)
url = 'http://api.calil.jp/library?appkey={}&pref={}'.format(calil_app_key, locate.encode('utf-8'))
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
libraries = soup.findAll('library')
for library_soup in libraries:
now_dict = OrderedDict()
for now_column in liblary_columns:
now_dict[now_column] = [library_soup.find(now_column).text]
df = df.append(pd.DataFrame(now_dict))
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
def one_city_libraries_df(pref, city):
df = pd.DataFrame(columns=liblary_columns)
url = 'http://api.calil.jp/library?appkey={}&pref={}&city={}'.format(calil_app_key, pref.encode('utf-8'), city.encode('utf-8'))
#print url
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
#print soup
libraries = soup.findAll('library')
for library_soup in libraries:
now_dict = OrderedDict()
for now_column in liblary_columns:
now_dict[now_column] = [library_soup.find(now_column).text]
df = df.append(pd.DataFrame(now_dict))
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
def city_libraries_df(locate):
url = 'http://geoapi.heartrails.com/api/xml?method=suggest&matching=like&keyword={}'.format(locate.encode('utf-8'))
r = requests.get(url)
soup = BeautifulSoup(r.content,"lxml")
#print soup, soup.find('error')
if soup.find('error'):
#市町村名じゃなかったら、近隣を探す
print locate,'付近の図書館を検索'
return near_libraries_df(locate)
else:
#市町村名なら県名と市町村名を得て、それで探す
pref = soup.find('prefecture').text
city = soup.find('city').text
#print pref, city
if u'区' in city:
#政令指定都市は区が入ってるので取り除く
city = re.sub(u'[^市]+区', '', city)
#print pref, city
print pref, city, '内の図書館を検索'
return one_city_libraries_df(pref, city)
prefectures = [u'北海道',u'青森県',u'岩手県',u'宮城県',u'秋田県',u'山形県',u'福島県',u'茨城県',u'栃木県',u'群馬県',
u'埼玉県',u'千葉県',u'東京都',u'神奈川県',u'新潟県',u'富山県',u'石川県',u'福井県',u'山梨県',u'長野県',
u'岐阜県',u'静岡県',u'愛知県',u'三重県',u'滋賀県',u'京都府',u'大阪府',u'兵庫県',u'奈良県',u'和歌山県',
u'鳥取県',u'島根県',u'岡山県',u'広島県',u'山口県',u'徳島県',u'香川県',u'愛媛県',u'高知県',u'福岡県',
u'佐賀県',u'長崎県',u'熊本県',u'大分県',u'宮崎県',u'鹿児島県',u'沖縄県']
def library_list(locate_list):
'''
地名のリストを渡して付近の図書館のリスト(館名、住所、電話、geocode、URLなど)のデータフレームを返す
'''
df = pd.DataFrame()
for locate in locate_list:
if locate in prefectures:
#県名のみなら県内の一覧を返す
df = df.append(prefecture_libraries_df(locate))
else:
df = df.append(city_libraries_df(locate))
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
import time
def get_library_data(df, now_systemid, request_column):
return df[df['systemid']==now_systemid][request_column].values[0]
def get_biblio_data(df, now_isbn, request_column):
return df[df['isbn']==now_isbn][request_column].values[0]
def library_status(biblio_df, library_df = ''):
'''
isbnを含むbiblioデータフレームと図書館リストのデータフレームを渡して、
isbn、タイトル、所蔵/貸し出し状況/予約URLについてデータフレームにまとめて返す
'''
isbn_list = [isbn for isbn in biblio_df['isbn']]
library_list = [library for library in library_df['systemid']]
df = pd.DataFrame(columns=['isbn','title','library','status','url'])
#一回目のリクエスト
api = 'http://api.calil.jp/check?appkey={}&isbn={}&systemid={}&format=xml'.format(calil_app_key, ','.join(isbn_list), ','.join(library_list))
r = requests.get(api)
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
#終了かどうか状況取得 0(偽)または1(真)。1の場合は、まだすべての取得が完了していない.
now_continue = soup.find('continue').text
while '0' not in now_continue:
#セッション情報取得
now_session = soup.find('session').text
#5秒待つ
time.sleep(5)
#再度のリクエスト
#print now_continue, "I'm waiting..."
api = 'http://api.calil.jp/check?appkey={}&session={}&format=xml'.format(calil_app_key, now_session)
r = requests.get(api)
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
now_continue = soup.find('continue').text
#ループを抜けたらパース処理
books = soup.findAll('book')
for booksoup in books:
now_isbn = dict(booksoup.attrs)['isbn']
#本ごとの下に各館の状況
librarysoups = booksoup.findAll('system')
for librarysoup in librarysoups:
#各館の下に貸出状況
now_systemid = dict(librarysoup.attrs)['systemid']
now_libkeys_soup = librarysoup.find('libkeys')
if now_libkeys_soup and now_libkeys_soup.text:
#libkeysがあれば本がある
now_libkeys = now_libkeys_soup.text
now_reserveurl = librarysoup.find('reserveurl').text
else:
now_libkeys = 'None'
now_reserveurl = 'None'
now_dict = OrderedDict()
now_dict['isbn'] = now_isbn,
now_dict['title'] = get_biblio_data(biblio_df, now_isbn, 'title'),
now_dict['library'] = get_library_data(library_df, now_systemid, 'formal'),
now_dict['status'] =now_libkeys,
now_dict['url'] =now_reserveurl,
df = df.append(pd.DataFrame(now_dict))
df = df[df['status']!='None']
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
アマゾンの在庫/最安値チェック¶
def amazon_stock_thisbook(keyword):
result_df = pd.DataFrame()
book_soups = item_search(keyword)
if book_soups:
for book_soup in book_soups:
result_dict = OrderedDict()
result_dict['asin'] = book_soup.find('asin').text,
result_dict['title'] = book_soup.find('title').text,
if book_soup.find('formattedprice'):
result_dict['listprice'] = book_soup.find('formattedprice').text,
offersummary_soup = book_soup.find('offersummary')
if offersummary_soup:
#print keyword, offersummary_soup
result_dict['totalnew'] = offersummary_soup.find('totalnew').text,
if offersummary_soup.find('lowestnewprice'):
result_dict['lowestnewprice'] = offersummary_soup.find('lowestnewprice').find('formattedprice').text,
else:
result_dict['lowestnewprice'] = 'None',
result_dict['totalused'] = offersummary_soup.find('totalused').text,
if offersummary_soup.find('lowestusedprice'):
result_dict['lowestusedprice'] = offersummary_soup.find('lowestusedprice').find('formattedprice').text,
else:
result_dict['lowestusedprice'] = 'None',
result_dict['url'] = 'http://www.amazon.co.jp/dp/{}/'.format(book_soup.find('asin').text)
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
def ciniibook_title(ncid):
url = 'http://ci.nii.ac.jp/ncid/{}'.format(ncid)
r = requests.get(url)
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
book_title_soup = soup.find('meta', attrs={'name':'dc.title'})
if book_title_soup:
return dict(book_title_soup.attrs)['content']
def amazon_stocks(biblio_df):
result_df = pd.DataFrame(columns=['asin','title','listprice','totalnew','lowestnewprice','totalused','lowestusedprice','url'])
for i in range(0, len(biblio_df)):
print '.',
if 'isbn' in biblio_df.columns:
isbn = isbn13to10(biblio_df['isbn'].iat[i])
elif 'asin' in biblio_df.columns:
isbn = biblio_df['asin'].iat[i]
else:
isbn = None
if 'ncid' in biblio_df.columns:
ncid = biblio_df['ncid'].iat[i]
else:
ncid = None
if 'title' in biblio_df.columns:
title = biblio_df['title'].iat[i]
else:
title = None
if isbn and len(amazon_stock_thisbook(isbn)):
result_df = result_df.append(amazon_stock_thisbook(isbn))
elif ncid and ciniibook_title(ncid):
result_df = result_df.append(amazon_stock_thisbook(ciniibook_title(ncid)))
elif len(amazon_stock_thisbook(unicode(title))):
result_df = result_df.append(amazon_stock_thisbook(unicode(title)))
else:
result_dict = OrderedDict()
result_dict['asin'] = isbn,
result_dict['title'] = title,
result_dict['listprice'] = 'None',
result_dict['totalnew'] = 'None',
result_dict['lowestnewprice'] = 'None',
result_dict['totalused'] ='None',
result_dict['lowestusedprice'] = 'None',
result_dict['url'] = 'None',
result_df = result_df.append(pd.DataFrame(result_dict))
result_df = result_df.sort_values(by='title')
result_df.index = range(1, len(result_df)+1) #最後にインデックスつけ
return result_df
日本の古本屋¶
class Kosho_info(library_info_list):
default_max_page = 100
#https://www.kosho.or.jp/products/list.php?transactionid=f933edac26fe92ced0cdfbbd118b58d90e5e59f9&mode=search_retry&pageno=2&search_pageno=1&product_id=&reset_baseinfo_id=&baseinfo_id=&product_class_id=&quantity=1&from_mode=&search_facet_publisher=&search_word=%E6%A0%AA%E5%BC%8F%E6%8A%95%E8%B3%87&search_name=&search_name_matchtype=like&search_author=&search_author_matchtype=like&search_publisher=&search_publisher_matchtype=like&search_isbn=&search_published_year_min=&search_published_year_max=&search_comment4=&search_comment4_matchtype=like&search_book_flg=&search_price_min=&search_price_max=&search_only_has_stock=1&search_orderby=score&search_sorttype=asc&search_page_max=20&search_image_disp=&search_orderby_navi=score&search_sorttype_navi=asc&search_page_max_navi=20&search_image_disp_navi=&transactionid=f933edac26fe92ced0cdfbbd118b58d90e5e59f9
def get_query(self, page, max_page):
return 'https://www.kosho.or.jp/products/list.php?mode=search_retry&pageno=' + str(page) + \
'&search_pageno=1&quantity=1&search_word=' + self.keyword + \
'&search_only_has_stock=1&search_orderby=score&search_sorttype=asc&search_page_max=' + str(max_page)
def make_resource_list(self):
last_page = self.get_hit_num() / self.max_onepage + 1
return [self.get_query(page, max_page = self.max_onepage) for page in range (1, last_page + 1)]
#<form name="form1"
# <!--★件数-->
#<div><span class="attention">134件</span>が見つかりました。</div>
def parse_hit_num(self, soup):
hit_soup = soup.find("form", id="form1")
recom = re.compile(u'([0-9]+)件が見つかりました。')
return recom.search(hit_soup.text)
#<div class="search_result_list product_list">
def get_item_soup(self, soup):
return soup.findAll("div", class_="search_result_list product_list")
#<a href="javascript:goDetail(5185060);">株式投資=はじめるまえの50の常識</a>
def get_detail_title(self, soup):
return soup.find('a', {'href':re.compile(r'javascript:goDetail.+')}).text.strip()
#https://www.kosho.or.jp/products/detail.php?product_id=5185060
def get_detail_url(self, soup):
title_soup = soup.find('a', {'href':re.compile(r'javascript:goDetail.+')})
recom = re.compile(r'javascript:goDetail\(([0-9]+)\);')
m = recom.search(dict(title_soup.attrs)['href'])
return 'https://www.kosho.or.jp/products/detail.php?product_id=' + m.group(1)
#<div class="product_info wide">または<div class="product_info">
def get_detail_productinfo(self, soup):
info_soup = soup.find("div", class_=re.compile(r'product_info.*'))
if info_soup:
return info_soup.text.replace('\n','').replace('\t','').strip()
else:
return ''
#<span class="price">3,500</span>
def get_detail_price(self, soup):
return soup.find('span', class_='price').text.strip()
#特異
def parse_data(self, soup):
result_dict = OrderedDict()
result_dict['title'] = self.get_detail_title(soup),
result_dict['info'] = self.get_detail_productinfo(soup),
result_dict['price'] = self.get_detail_price(soup),
result_dict['url'] = self.get_detail_url(soup),
return result_dict
class Kosho_info_title(Kosho_info):
#https://www.kosho.or.jp/products/list.php?
#mode=search_retry&pageno=&search_pageno=1&product_id=&reset_baseinfo_id=&
#baseinfo_id=&product_class_id=&quantity=1&from_mode=&search_facet_publisher=
#&search_word=&search_name=%E7%A9%BA%E3%81%AE%E8%89%B2%E3%81%AB%E3%81%AB%E3%81%A6%E3%81%84%E3%82%8B
def get_query(self, page, max_page):
return 'https://www.kosho.or.jp/products/list.php?' + \
'mode=search_retry&pageno=&search_pageno=1&product_id=&reset_baseinfo_id=&' + \
'baseinfo_id=&product_class_id=&quantity=1&from_mode=&search_facet_publisher=' + \
'&search_only_has_stock=1&search_word=&search_name=' +self.keyword
def kosho_stocks(biblio_df):
result_df = pd.DataFrame()
for i in range(0, len(biblio_df)):
title = biblio_df['title'].iat[i]
k = Kosho_info_title(title)
df = k.collector()
result_df = result_df.append(df)
result_df = result_df.sort_values(by='title')
result_df.index = range(1, len(result_df)+1) #最後にインデックスつけ
return result_df
国会図書館・各県立図書館¶
def house_books(soup):
#所蔵館と貸し出し状況
items = soup.findAll('dcndl:item')
#result = u'所蔵館数:' + unicode( len(items)) + '\n'
result_df = pd.DataFrame(columns=['title','library_name','availability','description','url'])
for item in items:
print '.',
result_dict = OrderedDict()
result_dict['title'] = soup.find('dcterms:title').text,
result_dict['library_name'] = item.find('foaf:name').text,
result_dict['availability'] = result_dict['description'] = result_dict['url'] ='',
if item.find('dcndl:availability'):
result_dict['availability'] = item.find('dcndl:availability').text,
if item.find('dcterms:description'):
result_dict['description'] = item.find('dcterms:description').text,
if item.find('rdfs:seealso'):
result_dict['url'] = dict(item.find('rdfs:seealso').attrs)['rdf:resource'] #各図書館の詳細ページ
result_df = result_df.append(pd.DataFrame(result_dict))
return result_df
def nbn2ndlurl(nbn):
url ='http://iss.ndl.go.jp/api/opensearch?jpno={}'.format(nbn)
#print url
try:
r = requests.get(url)
soup = BeautifulSoup(r.content, "lxml")
guid = soup.find('guid', ispermalink='true')
return guid.text
except:
return None
def ndl_stocks(df):
result_df = pd.DataFrame(columns=['title','library_name','availability','description','url'])
for nbn in df['nbn']:
url = nbn2ndlurl(nbn)
if url:
url_rdf = url + '.rdf'
r = requests.get(url_rdf)
soup = BeautifulSoup(r.content, "lxml")
result_df = result_df.append(house_books(soup))
result_df.index = range(1, len(result_df)+1) #最後にインデックスつけ
return result_df
国会図書館デジタルコレクション、複写サービス、外部リポジトリ¶
def ndl_collection(df):
result_df = pd.DataFrame()
basic_term_list = ['dcterms:title','dc:creator','dcterms:issued']
resource_list=[r'id.ndl.go.jp',r'dl.ndl.go.jp',r'ci.nii.ac.jp',r'jairo.nii.ac.jp']
for url in df['ndl_url']:
url_rdf = url + '.rdf'
r = requests.get(url_rdf)
soup = BeautifulSoup(r.content, "lxml")
#print soup
result_dict = OrderedDict()
for basic_term in basic_term_list:
if soup.find(basic_term):
result_dict[basic_term] = soup.find(basic_term).text,
else:
result_dict[basic_term] = '',
for resource in resource_list:
result_dict[resource] = ''
seealso_soups = soup.findAll('rdfs:seealso')
for seealso_soup in seealso_soups:
#print seealso_soup
seealso_url = dict(seealso_soup.attrs)['rdf:resource']
#print seealso_url
for resource in resource_list:
if resource in seealso_url:
#print resource
result_dict[resource] = seealso_url,
result_df = result_df.append(pd.DataFrame(result_dict))
result_df.index = range(1, len(result_df)+1) #最後にインデックスつけ
return result_df
Google検索¶
class Google_info(Searcher):
default_max_page = 50
# https://www.google.co.jp/search?q=[keyword]&num=10&start=10
def get_query(self, page, max_page):
return 'https://www.google.co.jp/search?q={}&num={}&start={}'.format(self.keyword.encode('utf-8'),max_page,page)
def make_resource_list(self):
last_page = 50
return [self.get_query(page, self.default_max_page) for page in range (0, last_page, self.default_max_page)]
def fetch_data(self, url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'}
r = requests.get(url, headers=headers)
tree = lxml.html.fromstring(r.content.decode('utf-8'))
h3_soups = tree.xpath('//h3[@class="r"]/a')
st_soups = tree.xpath('//span[@class="st"]')
df = pd.DataFrame()
for i_h3,i_st in zip(h3_soups, st_soups):
result_dict = OrderedDict()
result_dict['title'] = i_h3.text,
result_dict['summary'] = i_st.text_content(),
result_dict['url'] = i_h3.attrib['href'],
df = df.append(pd.DataFrame(result_dict))
return df
def arrange(self, df):
if not df.empty:
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
class Google_book_info(Google_info):
def get_query(self, page, max_page):
return 'https://www.google.co.jp/search?tbm=bks&q={}&num={}&start={}'\
.format(self.keyword.encode('utf-8'),max_page,page)
Graphviz関係¶
#インラインでdot言語を表示する
def embed_dot(dot_string, size=''):
G=pgv.AGraph(dot_string)
G.graph_attr.update(size='{}'.format(size))
G.layout()
output = cStringIO.StringIO()
G.draw(output, format='svg')
svg = output.getvalue()
output.close()
svg_core = BeautifulSoup(svg, 'lxml').find('svg')
return HTML(unicode(svg_core))
@register_cell_magic
def csv2dot(line, cell):
'''
コンマ区切りのテキストからネットワーク図をつくる
書式例:
%%csv2dot
角倉了以,日本大百科全書,角倉了以とその子
角倉了以,朝日日本歴史人物事典,「角倉文書」(『大日本史料』12編14所収)
角倉了以,参考調査便覧,宮本又次他『日本貿易人の系譜』有斐閣1980
'''
G = pgv.AGraph(strict=False,directed=True)
G.graph_attr.update(layout = 'dot', rankdir='LR', concentrate = 'true')
for line in cell.split('\n'):
items = line.split(',')
for i in range(len(items))[:-1]:
print items[i],'->', items[i+1]
G.add_edge(items[i], items[i+1])
return embed_dot(G.to_string())
@register_cell_magic
def indent2dot(line, cell):
'''
タブ区切りのインデント付きテキストからネットワーク図をつくる
書式例:
%%csv2dot
角倉了以
日本大百科全書
角倉了以とその子
朝日日本歴史人物事典
「角倉文書」(『大日本史料』12編14所収)
角倉了以とその子
参考調査便覧
宮本又次他『日本貿易人の系譜』有斐閣1980
'''
G = pgv.AGraph(strict=False,directed=True)
G.graph_attr.update(layout = 'dot', rankdir='LR', concentrate = 'true')
node_stack = [cell.split('\n')[0]]
for line in cell.split('\n')[1:]:
#print line, line.count(' ',0), len(node_stack),node_stack
if len(node_stack) < line.count(' ',0)+1:
#1つ下がる
node_stack.append(line.strip())
elif len(node_stack) == line.count(' ',0)+1:
#同じレベル
node_stack.pop()
node_stack.append(line.strip())
elif len(node_stack) > line.count(' ',0)+1:
node_stack.pop()
node_stack.pop()
node_stack.append(line.strip())
G.add_edge(node_stack[-2], node_stack[-1])
#print node_stack[-2],'->', node_stack[-1]
return embed_dot(G.to_string())
Thema Map by Wikipedia Category¶
class Thememap(object):
def __init__(self, first_keyword, max_level = 2):
self.G = pgv.AGraph(strict=False,directed=True)
self.first_keyword = first_keyword.decode('utf-8')
self.max_level = max_level
self.all_categories = []
self.node_links = {}
# キーワードを受けて上位概念のリストを返す
def fetch_category(self, keyword):
url = "https://ja.wikipedia.org/wiki/" + keyword
r = requests.get(url)
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
return_buffer = []
# 上位概念はカテゴリから抽出
#<div id="mw-normal-catlinks" class="mw-normal-catlinks">
# <li><a href="/wiki/Category:%E9%8A%80%E8%A1%8C" title="Category:銀行">銀行</a></li>
category_div_soup = soup.find("div", class_="mw-normal-catlinks")
if category_div_soup:
category_list_soup = category_div_soup.findAll("li")
for category_soup in category_list_soup:
return_buffer.append(category_soup.a.string)
return return_buffer
# def fetch_category(self, keyword):
# import wikipedia
# wikipedia.set_lang("ja")
# hit = wikipedia.page(keyword)
# return [c for c in hit.categories]
def regist_link(self, link_name, link_words):
# 短いリンクを優先
if not self.node_links.has_key(link_name):
self.node_links[link_name] = link_words
def dot(self, start_word, now_level):
if now_level > self.max_level:
return
else:
now_fetch_categories = self.fetch_category(start_word)
if now_fetch_categories:
for now_category in now_fetch_categories:
print '.',
# print now_category
if now_category in self.all_categories:
continue
else:
# print now_category のカテゴリ
link_word = start_word
start_word = start_word.replace(u'Category:','')
start_word = start_word.replace(u'のカテゴリ','')
self.regist_link(start_word, link_word)
if now_level+1 > self.max_level:
#枝の先は未処理になるのでここでリンクだけつくっておく
self.regist_link(now_category, u'Category:'+now_category)
#エッジを追加
self.G.add_edge(start_word, now_category)
#一度出てきたカテゴリは記録して重複を防ぐ
self.all_categories.append(now_category)
#下位レベルへ再帰
self.dot('Category:'+now_category, now_level+1)
def draw(self):
self.dot(self.first_keyword, 0)
# ノードごとにurlリンクをつける
for link_name, link_word in self.node_links.items():
self.G.add_node(link_name, shape = 'plaintext', href='https://ja.wikipedia.org/wiki/' + link_word)
self.G.graph_attr.update(layout = 'dot', rankdir='LR', concentrate = 'true')
return self.G.to_string()
Google Suggest Map¶
def uniq(seq):
seen = set()
seen_add = seen.add
return [ x for x in seq if x not in seen and not seen_add(x)]
class SuggestMap(object):
def __init__(self, keyword, expand_flag=0):
self.keyword = keyword
self.expand_flag = expand_flag
self.suggested_list = []
self.node_links = {}
self.row = "digraph{ graph[layout = neato, concentrate = true, overlap = false, splines = true];"
self.row += self.keyword +' [shape=circle];\n'
self.row += 'node [shape = plaintext];\n'
#googleサジェストで情報集め
def suggest(self, keyword):
suggested_list = []
tail_list = ['',' ','_']
# 時間はかかるけど豊かなマップが書けるオプション
if self.expand_flag == 1:
tail_list.extend([' ' + unichr(i+97) for i in range(26)]) #アルファベット全部
#2回めは添付しないとかなり時間は短縮できて結果は同じ
self.expand_flag = 0
elif self.expand_flag == 2:
tail_list.extend([' ' + unichr(i+12450) for i in range(89)]) #カタカナ全部
#2回めは添付しないとかなり時間は短縮できて結果は同じ
self.expand_flag = 0
for tail in tail_list:
url = "http://www.google.com/complete/search?hl=ja&q="+keyword+tail+"&output=toolbar"
#print url.encode('utf-8')
r = requests.get(url)
# print r.encoding
soup = BeautifulSoup(r.text.encode('utf-8'),"lxml")
#<suggestion data="機械翻訳 比較"/>
suggest_list_soup = soup.findAll("suggestion")
for suggest_soup in suggest_list_soup:
print '.',
now_suggested_text = dict(suggest_soup.attrs)['data']
now_suggested = keyword + ' ' + now_suggested_text
# 重複外し
now_suggested = ' '.join(uniq(now_suggested.split(' ')))
suggested_list.append(now_suggested)
return suggested_list
def regist_link(self, link_name, suggested_words):
# 短いリンクを優先
# print 'リンクする', link_name, suggested_words,len(suggested_words.split('+'))
if self.node_links.has_key(link_name):
# print 'リンク既出:', node_links[link_name],len(node_links[link_name].split(' '))
if len(self.node_links[link_name].split(' ')) > len(suggested_words.split(' ')):
# print 'よりシンプルなリンクなので:登録'
self.node_links[link_name] = suggested_words
else:
# print 'リンク初出:登録'
self.node_links[link_name] = suggested_words
def get_src_link(self, now_suggested):
# print now_suggested.encode('utf-8')
now_src = '"' + re.sub(r'[\s]+', '" -> "', now_suggested) + '";\n'
# 孔子 [href="http://ja.wikipedia.org/wiki/孔子"];
if now_suggested.split(' ')[-1] in self.keyword:
self.regist_link(now_suggested.split(' ')[0] ,now_suggested)
# print now_node_link.encode('utf-8')
else:
self.regist_link(now_suggested.split(' ')[-1] ,now_suggested)
return now_src
def draw(self):
first_list = self.suggest(self.keyword)
suggested_list = first_list
src = ''
for key in first_list:
for now_suggested in self.suggest(key):
src += self.get_src_link(now_suggested)
node_link_buffer = ''
for link_name, suggested_words in self.node_links.items():
node_link_buffer += '"'+ link_name + '" [href="https://www.google.co.jp/search?q='+suggested_words+'"];\n'
self.row += node_link_buffer + src + '}'
return self.row
関連マップの元¶
class RelateMap(object):
def __init__(self, keyword, max_depth, max_width):
print 'depth: ' + str(max_depth) + ' width: ' + str(max_width)
self.G = pgv.AGraph(strict=False,directed=True)
self.keyword = keyword
self.max_depth = max_depth
self.max_width = max_width
self.construct_graph()
def construct_graph(self):
start_nodes = self.get_start_node()
for start_node in start_nodes:
self.build_edges(start_node, 0)
self.set_nodes_attr()
self.set_graph_attr()
def build_edges(self, start_node, now_depth):
if now_depth >= self.max_depth:
return
for next_node in self.get_nextnodes(start_node):
print '.',
self.G.add_edge(start_node, next_node)
self.build_edges(next_node, now_depth +1)
def set_nodes_attr(self):
for n in self.G.nodes():
print '.',
nlabel = self.get_node_label(n)
nxlabel = self.get_node_xlabel(n)
nshape = self.get_node_shape(n)
nhref = self.get_node_href(n)
nimage = self.get_node_image(n)
self.G.add_node(n, label = nlabel, bottomlabel= nxlabel, shape = nshape, href = nhref, image =nimage)
def get_node_label(self, node):
return node
def get_node_xlabel(self, node):
return ''
def get_node_shape(self, node):
return 'plaintext'
def get_node_href(self, node):
return ''
def get_node_image(self, node):
return ''
def set_graph_attr(self):
self.G.graph_attr.update(layout = 'neato', rankdir='LR', concentrate = 'true', overlap = 'false', splines = 'true')
def g(self):
'''
グラフを描写してHTMLに埋め込むメソッド
'''
return embed_dot(self.G.to_string())
def df(self):
'''
データフレーム(表)に書き出すメソッド
'''
#ノードの属性(辞書になってる)を取り出してコラム名に設定する
column_names = self.G.nodes()[0].attr.keys()
df = pd.DataFrame(columns=column_names)
for n in self.G.nodes():
result_dict = OrderedDict()
result_dict['node'] = n,
for column_name in column_names:
result_dict[column_name] = self.G.get_node(n).attr[column_name],
df = df.append(pd.DataFrame(result_dict))
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
Amazon商品情報による関連マップ¶
class AmazonRelateMap(RelateMap):
title_dict = {}
def get_start_node(self):
items = item_search(self.keyword, item_page = 1)[:self.max_width]
return [item.find('asin').text for item in items]
def get_nextnodes(self, asin):
'''
asinを受けて類似本のasinのリストを返す
'''
items = item_search(asin, item_page = 1)
result = []
if items:
item = items[0]
self.title_dict[asin] = item.find('title').text
for similarproduct in item.findAll('similarproduct')[:self.max_width]:
similar_asin = similarproduct.find('asin').text
similar_title = similarproduct.find('title').text
self.title_dict[similar_asin] = similar_title
result.append(similar_asin)
return result
def get_node_label(self, asin):
return self.title_dict[asin]
def get_node_href(self, asin):
return 'http://www.amazon.co.jp/dp/' + str(asin)
def set_graph_attr(self):
self.G.graph_attr.update(layout = 'sfdp', rankdir='LR', concentrate = 'true', overlap = 'false', splines = 'true')
def df(self):
'''
データフレーム(表)に書き出すメソッド
'''
#スーパークラスのメソッドをそのまま使う
df = super(AmazonRelateMap, self).df()
#カラム名をつけかえ
df.columns = ['url', 'title', 'asin','shape']
return df
Amazon商品情報による関連マップ (商品画像付き)¶
class AmazonPictureRelateMap(AmazonRelateMap):
def image_download(self, asin, url):
'''
表紙イメージを (asin).jpgという名前でダウンロード
'''
with open(asin + '.jpg', "wb") as f:
r = requests.get(url, headers=headers)
f.write(r.content)
def get_image_url(self, asin):
items = item_search(asin, item_page = 1)
if items and items[0].find('largeimage'):
return items[0].find('largeimage').find('url').text
else:
return ''
def get_node_image(self, asin):
url = self.get_image_url(asin)
if url:
self.image_download(asin, url)
return asin + '.jpg'
else:
return ''
def set_nodes_attr(self):
for n in self.G.nodes():
print '.',
nlabel = self.get_node_label(n)
nxlabel = self.get_node_xlabel(n)
nshape = self.get_node_shape(n)
nhref = self.get_node_href(n)
nimage = self.get_node_image(n)
if nimage:
#self.G.add_node(n, label = nlabel, shape = nshape, href = nhref, image =nimage, labelloc='b')
self.G.add_node(n, label = '', shape = nshape, href = nhref, image =nimage)
else:
self.G.add_node(n, label = nlabel, shape = nshape, href = nhref)
def df(self):
'''
データフレーム(表)に書き出すメソッド
'''
#スーパークラスのメソッドをそのまま使う
df = super(AmazonRelateMap, self).df()
df['label'] = [self.title_dict[asin] for asin in df['node']]
#カラム名をつけかえ
#href image label node shape
df.columns = ['url', 'image', 'title','asin','shape']
return df
コトバンク関連キーワードによる関連マップ¶
class KotobankRelateMap(RelateMap):
start_node = ''
title_dict = dict()
def get_start_node(self):
self.start_node ='/word/' + urllib2.quote(self.keyword.encode('utf-8'))
return self.start_node,
def get_nextnodes(self, parturl):
'''
urlを受けて関連語のurlのリストを返す
'''
#print parturl
result = []
#url = 'https://kotobank.jp/word/%E7%B5%8C%E6%B8%88%E4%BA%88%E6%B8%AC-58788'
r = requests.get('https://kotobank.jp' + parturl)
tree = lxml.html.fromstring(r.content)
this_title_tree = tree.xpath('//*[@id="mainTitle"]/h1/b')
#print this_title_tree[0].text
if this_title_tree:
self.title_dict[parturl] = this_title_tree[0].text
else:
return None
links = tree.xpath('//*[@id="retailkeyword"]/a')
for link in links:
similar_title = link.text #予測
similar_url = link.attrib['href'] # /word/%E4%BA%88%E6%B8%AC-406123
self.title_dict[similar_url] = similar_title
result.append(similar_url)
return result
def get_node_href(self, parturl):
return 'https://kotobank.jp' + parturl
def get_node_label(self, parturl):
return self.title_dict.get(parturl)
def set_nodes_attr(self):
super(KotobankRelateMap, self).set_nodes_attr()
self.G.add_node(self.start_node, label = self.keyword, shape = 'circle')
Weblio関連用語による関連マップ¶
class WeblioRelateMap(RelateMap):
start_node = ''
title_dict = dict()
def get_start_node(self):
self.start_node ='http://www.weblio.jp/content/' + urllib2.quote(self.keyword.encode('utf-8'))
return self.start_node,
def get_nextnodes(self, url):
'''
urlを受けて関連語のurlのリストを返す
'''
#print url
result = []
# http://www.weblio.jp/content/%E4%BA%88%E6%B8%AC
r = requests.get(url)
tree = lxml.html.fromstring(r.content)
this_title_tree = tree.xpath('//*[@id="topicWrp"]/span' )
#print this_title_tree[0].text
if this_title_tree:
self.title_dict[url] = this_title_tree[0].text
else:
return None
links = tree.xpath('//div[@class="sideRWordsL"]/a')
for link in links:
similar_title = link.text #予測
similar_url = link.attrib['href']
self.title_dict[similar_url] = similar_title
result.append(similar_url)
return result
def get_node_href(self, url):
return url
def get_node_label(self, url):
return self.title_dict.get(url)
def set_nodes_attr(self):
super(WeblioRelateMap, self).set_nodes_attr()
self.G.add_node(self.start_node, label = self.keyword, shape = 'circle')
エクステンションで独自のマジックコマンドを定義¶
#selectindexのための補助関数
def string2index(nowlist):
resultlist = []
for item in nowlist:
item = item.strip()
if item.isdigit():
item = int(item)
resultlist.append(item)
else:
if ':' in item:
innrt_item = item.split(':')
if innrt_item[0].isdigit() and innrt_item[1].isdigit():
item = range(int(innrt_item[0]), int(innrt_item[1])+1)
resultlist.extend(item)
return resultlist
from IPython.core.magic import (Magics, magics_class, line_magic,
cell_magic, line_cell_magic)
# The class MUST call this class decorator at creation time
@magics_class
class MyMagics(Magics):
def line2value(self, line):
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
return now_user_namespace[line]
else:
return line.encode('utf-8')
def line2df(self, f, line):
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return f(now_variable)
else:
return line + u' is not DataFrame, but ' + str(type(now_variable))
else:
return line + u' is not defined.'
@line_magic
def epwing(self, line):
e = epwing_info(self.line2value(line))
df = e.collector()
return df
@line_magic
def kotobank(self, line):
k = Kotobank_info(self.line2value(line))
df = k.collector()
return df
@line_magic
def dictj(self, line):
line = self.line2value(line)
e = epwing_info(line)
df = e.collector()
df['url'] = '(epwing)'
k = Kotobank_info(line)
df = df.append(k.collector())
w = Wikipedia_Info(line.decode('utf-8'), 'ja')
df = df.append(w.fetch_page())
df = df.sort_values(by='des_size') #並べ替え
df.index = range(1, len(df)+1) #最後にインデックスつけ
return df
@line_magic
def encyclopediacom(self, line):
k = encyclopediacom_info(self.line2value(line))
df = k.collector()
return df
#en English
@line_magic
def wikipedia_e(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'en')
return w.fetch_page()
#simple Simple English
@line_magic
def wikipedia_s(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'simple')
return w.fetch_page()
#de Deutsch
@line_magic
def wikipedia_de(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'de')
return w.fetch_page()
#fr français
@line_magic
def wikipedia_fr(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'fr')
return w.fetch_page()
#es español
@line_magic
def wikipedia_es(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'es')
return w.fetch_page()
#ru русский
@line_magic
def wikipedia_fr(self, line):
w = Wikipedia_Info(unicode(self.line2value(line)),'ru')
return w.fetch_page()
@line_magic
def wikipedia_j(self, line):
w = Wikipedia_Info(self.line2value(line).decode('utf-8'),'ja')
return w.fetch_page()
@line_magic
def ndl(self, line):
w = ndl_list_info(self.line2value(line).decode('utf-8'))
df = w.collector()
return df
@line_magic
def cinii_list(self, line):
w = CiNii_list_info(self.line2value(line))
df = w.collector()
return df
@line_magic
def webcat(self, line):
'''
webcat plus minusを使って書籍等を検索して、結果をデータフレームにする
'''
w = webcat_list_info(self.line2value(line))
df = w.collector()
return df
@line_magic
def worldcat(self, line):
w = Worldcat_list_info(self.line2value(line))
df = w.collector()
return df
@line_magic
def reflist(self, line):
r = refcases_list_info(self.line2value(line).decode('utf-8'))
df = r.collector()
return df
@line_magic
def refcase(self, line):
'''
レファレンス協同データベースを検索して、データフレームを返す
書式:
%refcase (keyword),[num]
keyword:検索語(必須)
num: 最大表示件数(デフォルト10件)
例:角倉了以に関するレファレンス事例を10件分表示する
%refcase 角倉了以
例:角倉了以に関するレファレンス事例を5件分表示する
%refcase 角倉了以,5
'''
line_items = self.line2valuelist(line)
if len(line_items) > 1:
now_max_num = int(line_items[1])
else:
now_max_num = 10
r = Refcases_info(line_items[0].decode('utf-8'), now_max_num)
df = r.collector()
df = pd.concat([df.ix[:,5:12], df.ix[:,20:21]], axis=1)
return df
@line_magic
def eb(self, line):
'''
データフレームを全件表示、URLはリンクかしてHTMLに埋め込んで表示
書式:
%eb df
例:直近の結果であるデータフレームを埋め込む
%eb _
例:Out[3]の結果であるデータフレームを埋め込む
%eb _3
'''
return self.line2df(embed_df, line)
@line_magic
def html2df(self, line):
'''
HTMLに埋め込んだデータからデータフレームに変換する
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'IPython.core.display.HTML' in str(type(now_variable)):
return pd.read_html(StringIO(now_variable.data), index_col =0, header=0)[0]
else:
return line + u' is not HTML, but ' + str(type(now_variable))
else:
return line + u' is not defined.'
#書誌データフレームの目次を複数の列に展開する
@line_magic
def expand_content(self,line):
'''
データフレームに含まれる目次項目を展開する
書式:
%exp_cont df
例:直近の結果であるデータフレームに含まれる目次項目を展開する
%exp_cont _
例:Out[3]の結果であるデータフレームに含まれる目次項目を展開する
%exp_cont _3
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
df = now_user_namespace[line]
if 'DataFrame' in str(type(df)):
if 'contents' in df.columns:
split_contents_df = df['contents'].str.split('\t', n=0, expand=True).fillna(value='')
return pd.concat([df[['title','summary']], split_contents_df],axis=1)
else:
return df
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def extbook(self, line):
'''
データフレームに含まれる書名(『書名』こういう形式のもの)を抜き出してデータフレームにして返す
書式:
%extbook df
例:直近の結果であるデータフレームに含まれる書名を抜き出してデータフレームに
%extbook _
例:Out[3]の結果であるデータフレームに含まれる書名を抜き出してデータフレームに
%extbook _3
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return ext_book(now_variable)
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def amazonreviews(self, line):
'''
isbnが含まれるデータフレームを受け取り、アマゾンレビューのデータフレームを返す
書式:
%reviews df
例:直近の結果であるデータフレームからisbnを受け取りアマゾンレビューのデータフレームを返す
%reviews _
例:Out[3]の結果であるデータフレームからisbnを受け取りアマゾンレビューのデータフレームを返す
%reviews _3
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
a = amazon_reviews(now_variable)
return a.collector()
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def stocks_amazon(self, line):
'''
書誌データフレームを受け、アマゾンの在庫と最安値の一覧表をデータフレームで返す
返り値:DataFrame
書式: %stocks_amazon biblio_df ……
例:out[1]の書誌データフレームに出てくる本を探しアマゾンの在庫と最安値の一覧表をデータフレームで返す
%stocks_amazon _1
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return amazon_stocks(now_variable)
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def stocks_kosho(self, line):
'''
書誌データフレームを受け、『日本の古本屋』に出品している書籍、出品店、値段などをデータフレームで返す
返り値:DataFrame
書式: %stocks_amazon biblio_df ……
例:out[1]の書誌データフレームに出てくる本を探し出品している書籍、出品店、値段などをデータフレームで返す
%stocks_kosho _1
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return kosho_stocks(now_variable)
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def stocks_ndl(self, line):
'''
書誌データフレームを受け、
国会図書館、各県立図書館の所蔵/貸し出し状況/予約URLについてデータフレームにまとめて返す
返り値:DataFrame
書式: %stocks_ndl biblio_df
例:out[1]の書誌データフレームに出てくる本を探し
国会図書館、各県立図書館の所蔵/貸し出し状況/予約URLについてデータフレームにまとめて返す
%stocks_ndl _1
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return ndl_stocks(now_variable)
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def ndlcollection(self, line):
'''
書誌データフレームを受け、
国会図書館デジタルコレクション、国会図書館複写サービス、外部リポジトリCiNii, JAIRO等へのリンク
をまとめた表をデータフレームで返す
返り値:DataFrame
書式: %ndlcollection biblio_df
例:out[1]の書誌データフレームに出てくる本を探し
デジタルコレクション、国会図書館複写サービス、外部リポジトリCiNii, JAIRO等へのリンク
をまとめた表をデータフレームで返す
%ndlcollection _1
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
return ndl_collection(now_variable)
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def librarystatus(self, line):
'''
isbnを含むbiblioデータフレームと図書館リストのデータフレームを渡して、
isbn、タイトル、所蔵/貸し出し状況/予約URLについてデータフレームにまとめて返す
返り値:DataFrame
書式: %librarystatus biblio_df, library_df
biblio_df %makebibでできるi書誌情報のデータフレーム
library_df %librarylistでできる図書館リストのデータフレーム
例:Out[1],Out[3],Out[7]のブックリストをまとめてデータフレームb_dfをつくり、
「淀屋橋駅」付近の図書館の所蔵/貸し出し状況/予約URLのデータフレームをつくる
b_df = %makebib _1, _3, _7
l_df = %librarylist 淀屋橋駅
%librarystatus b_df, l_df
'''
now_user_namespace = self.shell.user_ns
if len(line.split(',')) == 2:
bib_df_name = line.split(',')[0].strip()
lib_df_name = line.split(',')[1].strip()
if bib_df_name in now_user_namespace.keys() and lib_df_name in now_user_namespace.keys():
bib_df = now_user_namespace[bib_df_name]
lib_df = now_user_namespace[lib_df_name]
if 'DataFrame' in str(type(bib_df)) and 'DataFrame' in str(type(lib_df)):
return library_status(bib_df, lib_df)
else:
print 'not DataFrame'
return
else:
print item, 'not defined.'
return
elif len(line.split(',')) == 1:
bib_df_name = line.split(',')[0].strip()
if bib_df_name in now_user_namespace.keys():
bib_df = now_user_namespace[bib_df_name]
if 'DataFrame' in str(type(bib_df)):
return library_status(bib_df)
else:
print 'not DataFrame'
return
else:
print item, 'not defined.'
return
#選択系ツール
@line_magic
def selectstr(self, line):
'''
与えたデータフレームから、コラム名で指定した列(コラム/フィールド)に検索文字列が含まれるものを抜き出す
返り値:DataFrame
書式:
%selectstr DataFrame, column_name, search_string
DataFrame データフレーム
column_name コラム(フィールド)
search_string 検索文字列
例:直近の出力結果(データフレーム)から、titleフィールドに「文化祭」が含まれているものを抜き出す
%selectstr _, title, 文化祭
'''
now_user_namespace = self.shell.user_ns
df_name = line.split(',')[0].strip()
column_name = line.split(',')[1].strip()
search_string = line.split(',')[2].strip()
if df_name in now_user_namespace.keys():
df = now_user_namespace[df_name]
if 'DataFrame' in str(type(df)):
return df[df[column_name].str.contains(search_string)]
else:
print df_name, 'is not DataFrame, but ', type(df)
return
else:
print df_name, 'is not defined.'
return
@line_magic
def selectcolumn(self, line):
'''
与えたデータフレームから、コラム名で指定した列(コラム/フィールド)を抜き出す
返り値:DataFrame
書式
%selectcolumn DataFrame, column_name1, column_name2, column_name3, ....
DataFrame データフレーム
column_name1 コラム名その1
column_name2 コラム名その2
……
例:直近の結果(データフレーム)から「title」「summary」「contents」の列を抜き出す
%selectcolumn _94, 'title','summary','contents'
'''
now_user_namespace = self.shell.user_ns
df_name = line.split(',')[0].strip()
column_names = line.split(',')[1:]
select_columns = [col.strip() for col in column_names]
if df_name in now_user_namespace.keys():
df = now_user_namespace[df_name]
if 'DataFrame' in str(type(df)):
return df[select_columns]
else:
print df_name, 'is not DataFrame, but ', type(df)
return
else:
print df_name, 'is not defined.'
return
@line_magic
def selectindex(self, line):
'''
与えたデータフレームから、index番号で指定された行を抜き出す
返り値:DataFrame
書式
%selectindex DataFrame, index_num1, index_num2, ....
DataFrame データフレーム
index_num1 index番号その1
index_num2 index番号その2
……
例:直近の結果(データフレーム)から1,4〜7,10行目を抜き出す
%selectcol _94, 1,4:7,10
'''
now_user_namespace = self.shell.user_ns
df_name = line.split(',')[0].strip()
index_names = line.split(',')[1:]
#select_indexs = [int(idx) for idx in index_names]
select_indexs = string2index(index_names)
#print select_indexs
if df_name in now_user_namespace.keys():
df = now_user_namespace[df_name]
if 'DataFrame' in str(type(df)):
return df.query("index == {}".format(select_indexs))
else:
print df_name, 'is not DataFrame, but ', type(df)
return
else:
print df_name, 'is not defined.'
return
@line_magic
def makebib(self, line):
'''
ブックリスト系のデータフレームを複数受け重複を除き、webcat詳細ページから得た情報で書誌データフレームを完成させる
返り値:DataFrame
書式: %makebib df1, df2, df3, ……
例:out[1]とout[3]とout[7]の書誌情報(isbn, webcatのurl、titleなど)を含むデータフレームを統合し
書誌データフレームを完成させる
%makebib _1, _3, _7
'''
now_user_namespace = self.shell.user_ns
#print list(now_user_namespace.keys())
now_list = []
for item in line.split(','):
item = item.strip()
if item in now_user_namespace.keys():
now_variable = now_user_namespace[item]
if 'DataFrame' in str(type(now_variable)):
now_list.append(now_variable)
else:
print item, 'is not DataFrame, but ', type(now_variable)
return
else:
print item, 'is not defined.'
return
#print type(now_list)
return make_biblio(now_list)
@line_magic
def concatdf(self, line):
'''
データフレームを複数受けて、マージする
返り値:DataFrame
書式: %margedf df1, df2, df3, ……
'''
now_user_namespace = self.shell.user_ns
#print list(now_user_namespace.keys())
now_list = []
for item in line.split(','):
item = item.strip()
if item in now_user_namespace.keys():
now_variable = now_user_namespace[item]
if 'DataFrame' in str(type(now_variable)):
now_list.append(now_variable)
else:
print item, 'is not DataFrame, but ', type(now_variable)
return
else:
print item, 'is not defined.'
return
#print type(now_list)
return pd.concat(now_list)
@line_magic
def df2csv(self, line):
'''
データフレームをcsvに変換する
'''
now_user_namespace = self.shell.user_ns
if line in now_user_namespace:
now_variable = now_user_namespace[line]
if 'DataFrame' in str(type(now_variable)):
output = cStringIO.StringIO()
now_variable.to_csv(output, index=False, encoding='utf-8')
print output.getvalue()
return output.getvalue().decode('utf-8')
else:
print line, 'is not DataFrame, but ', type(now_variable)
@line_magic
def kosho(self, line):
k = Kosho_info(self.line2value(line))
df = k.collector()
return df
@line_magic
def koshotitle(self, line):
k = Kosho_info_title(self.line2value(line))
df = k.collector()
return df
@line_magic
def google(self, line):
w = Google_info(self.line2value(line).decode('utf-8'))
df = w.collector()
return df
@line_magic
def googlebook(self, line):
w = Google_book_info(self.line2value(line).decode('utf-8'))
df = w.collector()
return df
@line_magic
def thememap(self, line):
'''
WIkipediaのカテゴリー情報をつかってテーママップ(概念階層図)を描く
書式:%thememap keyword
例: %suggestmap 深層学習
'''
m = Thememap(self.line2value(line))
g = m.draw()
return embed_dot(g)
@line_magic
def suggestmap(self, line):
'''
googleサジェストをつかって検索語の共起語を得てマップを描く
書式:
%suggestmap keyword [,1 or 2]
例:ノーマルモードで検索語の共起語を得てマップを描く
%suggestmap 深層学習
例:エキスパンドモードでより網羅的に検索語の共起語を得てマップを描く
%suggestmap 深層学習,1
例:スーパーモードでさらに網羅的に検索語の共起語を得てマップを描く
%suggestmap 深層学習,2
'''
split_line = line.split(',')
if len(split_line) == 1:
print 'normal mode'
m = SuggestMap(unicode(self.line2value(line).decode('utf-8')),0)
g = m.draw()
return embed_dot(g)
elif len(split_line) == 2 and split_line[1] in u'1':
print 'expand mode'
m = SuggestMap(unicode(self.line2value(split_line[0]).decode('utf-8')),1)
g = m.draw()
return embed_dot(g)
elif len(split_line) == 2 and split_line[1] in u'2':
print 'super mode'
m = SuggestMap(unicode(self.line2value(split_line[0]).decode('utf-8')),2)
g = m.draw()
return embed_dot(g)
else:
print 'mode error - see %suggestmap?'
def line2valuelist(self, lines):
return [self.line2value(line) for line in lines.split(',')]
@line_magic
def wikipedia(self, line):
'''
言語を指定してWikipediaを検索する
書式:
%wikipedia keyword, langueage
keyword: 検索語(必須)
langueage : 言語指定(ja, en, de, ...)
'''
line_items = self.line2valuelist(line)
#print line_items
keyword = line_items[0].strip()
language = line_items[1].strip()
print keyword, language
w = Wikipedia_Info(keyword.decode('utf-8'), language)
return w.fetch_page()
@line_magic
def amazonmap(self, line):
'''
Amazon Product Advertising APIを使って関連商品(Similarities)の関連図をつくる
書式:
%amazonmap keyword, depth, start_num
keyword: 検索語(必須)
depth: 探索の深さ(デフォルト値 2)
width: 探索の広がり (デフォルト値 5)
使用例
%amazonmap 文化祭企画
%amazonmap 深層学習, 3, 3
'''
line_items = self.line2valuelist(line)
if len(line_items) > 1:
now_max_level = int(line_items[1])
else:
now_max_level = 1
if len(line_items) > 2:
now_start_num= int(line_items[2])
else:
now_start_num = 5
return AmazonRelateMap(unicode(line_items[0].decode('utf-8')), max_depth=now_max_level, max_width = now_start_num)
@line_magic
def amazonPmap(self, line):
'''
Amazon Product Advertising APIを使って関連商品(Similarities)の関連図(表紙画像)をつくる
書式:
%amazonmap keyword, depth, start_num
keyword: 検索語(必須)
depth: 探索の深さ(デフォルト値 2)
width: 探索の広がり (デフォルト値 5)
使用例
%amazonPmap 文化祭企画
%amazonPmap 深層学習, 3, 3
'''
line_items = self.line2valuelist(line)
if len(line_items) > 1:
now_max_level = int(line_items[1])
else:
now_max_level = 1
if len(line_items) > 2:
now_start_num= int(line_items[2])
else:
now_start_num = 5
return AmazonPictureRelateMap(unicode(line_items[0].decode('utf-8')), max_depth=now_max_level, max_width = now_start_num)
@line_magic
def kotobankmap(self, line):
'''
kotobankの関連キーワードをつかって関連図をつくる
書式:
%kotobankmap keyword, depth
keyword: 検索語(必須)
depth: 探索の深さ(デフォルト値 2)
使用例
%kotobankmap 文化祭企画
%kotobankmap 深層学習, 2
'''
line_items = self.line2valuelist(line)
if len(line_items) > 1:
now_max_level = int(line_items[1])
else:
now_max_level = 2
#print line_items[0],type(line_items[0])
k = KotobankRelateMap(unicode(line_items[0].decode('utf-8')), max_depth=now_max_level, max_width = 0)
return k.g()
@line_magic
def webliomap(self, line):
'''
Weblioの関連キーワードをつかって関連図をつくる
書式:
%webliomap keyword, depth
keyword: 検索語(必須)
depth: 探索の深さ(デフォルト値 2)
使用例
%webliomap 文化祭企画
%webliomap 深層学習, 3
'''
line_items = self.line2valuelist(line)
if len(line_items) > 1:
now_max_level = int(line_items[1])
else:
now_max_level = 2
w = WeblioRelateMap(unicode(line_items[0].decode('utf-8')), max_depth=now_max_level, max_width = 0)
return w.g()
@line_magic
def librarylist(self, line):
'''
地名のリストを渡して付近の図書館のリスト(館名、住所、電話、geocode、URLなど)のデータフレームを返す
返り値:DataFrame
書式
%librarylist address1, address2, address3, ....
DataFrame データフレーム
index_number1 行(index)番号その1
index_number2 行(index)番号その2
……
例:立ち寄り先3箇所(京都市北区 大阪市西区 神戸市中央区)の付近の
図書館のリスト(館名、住所、電話、geocode、URLなど)のデータフレームを返す
%librarylist 京都市北区, 大阪市西区, 神戸市中央区
'''
now_list = self.line2valuelist(line)
return library_list([i.decode('utf-8') for i in now_list])
@line_magic
def extamazon(self, line):
'''
urlで指定されるページからamazon.co.jpへのリンクを抽出してtitle, asinのデータフレームを返す
'''
return ext_amazon(self.line2value(line))
@line_magic
def interlang(self, line):
'''
wikipediaの「他の言語へのリンク」を使って各語の訳語をデータフレームで返す
'''
return interlanguage(self.line2value(line))
# @line_magic
# def lmagic(self, line):
# "my line magic"
# print("Full access to the main IPython object:", self.shell)
# print("Variables in the user namespace:", list(self.shell.user_ns.keys()))
# return line
# In order to actually use these magics, you must register them with a
# running IPython. This code must be placed in a file that is loaded once
# IPython is up and running:
ip = get_ipython()
# You can register the class itself without instantiating it. IPython will
# call the default constructor on it.
ip.register_magics(MyMagics)
#ここで登録したマジックコマンドは、load_ipython_extensionしなくていい
def load_ipython_extension(ipython):
ipython.register_magic_function(text2bib, 'cell')
ipython.register_magic_function(csv2df, 'cell')
ipython.register_magic_function(csv2dot, 'cell')
ipython.register_magic_function(indent2dot, 'cell')
使用例¶
使用例として、辞書にも載ってそうな枯れたトピックとして「角倉了以」について調べたい。
入力の手間を省く¶
Jupyter notebookは、ipythonから受け継いだタブキーによる補完機能がある。 MonkeyBenchのためのコマンドは%はじまりだから、%と頭の1〜2文字を入力してタブキーを押すと該当のコマンドを選択できるようになる。
またJupyter notebookでは、「_ 」アンダーバーで直前の出力を、アンダーバー+番号で番号の出力(たとえば「_55」でOut[55])を参照できる。
あと、繰り返し入力するとすればトピックである「角倉了以」なので、これは変数に代入しておく。
t = '角倉了以'
%themamap¶
リサーチ・ナビ(http://rnavi.ndl.go.jp/rnavi/ )が提供しているテーママップは、上位概念や上位カテゴリーを図解化してくれる。 同じことをウィキペディアのカテゴリー情報を使って実現したのが次のコマンド、%themamapである。 それぞれのノードはウィキペディアの該当項目にリンクされているので、リンク先で概要を確認することもできる。
テーママップについては下記の記事を参照
- 図書館となら、できること/レポートの時間 つづき 読書猿Classic: between / beyond readers
%thememap t
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
%suggestmap¶
googleのサジェスト機能には、過去のユーザーがキーワードを入力した頻度が反映されて、あのキーワードを検索した人たちが、同時に入力した言葉が出てくる。いろんな人がどうやって/どんな言葉で調べものをしたのか、を煮詰めたもので、集合知というには大げさだけど、その切れっ端くらいではある。
次のコマンド %suggestmapは、サジェスト機能を使って、検索時の共起キーワードを収集して、マップ化する。
まったく未知の分野の事項を調べる場合、どんな言葉を付帯させたらいいか知ることができる。
それぞれのノードをクリックすると、その該当の言葉の組み合わせでgoogle検索できるようにしてあるのでネット調査の橋頭堡として使うことができる。
サジェストマップについては次の記事を参照
- 検索と〈探しもの〉の力を拡張する、レトリックが教える3つの考え方ー図書館となら、できること 読書猿Classic: between / beyond readers
%suggestmap t
normal mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
少し寂しいので、オプションを与えてもう少し詳しいマップを描いてみる
%suggestmap t,1
expand mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
%kotobankmap¶
コトバンク(https://kotobank.jp/ ) は、VOYAGEGROUPと朝日新聞社が運営する無料ウェブ百科事典。
%kotobankmapは、コトバンクが提供する関連キーワードをつかってトピック周りの関連語をマップ化する。
ノードのリンクは、コトバンクの該当項目へのリンクがついており、リンク先で概要を確認できる。
%kotobankmap t
depth: 2 width: 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
%webliomap¶
%webliomapは、Weblioが提供する関連用語をつかってトピック周りの関連語をマップ化する。
ノードのリンクは、Weblioの該当項目へのリンクがついており、リンク先で概要を確認できる。
%webliomap t
depth: 2 width: 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
角倉了以と互いに矢印で結ばれた吉田光由は「塵劫記」を著したあの光由で、親類(角倉了以と光由の祖父は従兄弟)。
%reflist, %refcase¶
レファレンス協同データベースは、公共図書館、大学図書館、学校図書館、専門図書館等におけるレファレンス事例(言わば「調べもののプロ」の実践例)を蓄積し、インターネットを通じて提供する、調べ物のためのデータベース。
コマンド %reflistは、キーワードに関するレファレンス事例の一覧を、%refcaseはレファレンス事例の詳細を収集して表示する。
%reflist t
.
| title | detail_url | |
|---|---|---|
| 1 | 角倉了以(すみのくらりょうい)の墓はなぜ大悲閣(だいひかく)ではなく二尊院にある.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 2 | 京都の三長者について知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 3 | 角倉了以について知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 4 | 吉田了意という人物が、水運をひらいたかどうか知りたい。また、京都の川船の呼び名を.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 5 | a)角倉了以についての資料はないか。\nb)利根川沿革史または河川改修史のような資.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 6 | 1 十石舟・三十石船の成り立ちや歴史を知りたい。\n2 十石舟の現在の航路を知りた.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 7 | 伊藤仁斎について知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 8 | 徳川家康が江戸に幕府を開く頃に、堺・近江・京からたくさんの商人が移住している。\n.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 9 | 来住法悦の生涯について知りたい | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 10 | 角倉玄之(素庵)の長子の玄紀(はるのり)が京角倉家を、次子の厳昭(かねあき)が嵯.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 11 | 角倉素庵について知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 12 | 富士川舟運について知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 13 | 甲斐の国と塩の関係について知りたい。山梨では昔どのようにして塩を手に入れていたの.... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
| 14 | 正眼寺紙本墨書安南(あんなん)国書の概要を知りたい。 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
角倉了以に関連するレファレンス事例は14件あった。次のコマンドで、上位6件を、収集・表示する。
%refcase t,6
. . . . . . .
| 質問(Question) | 回答(Answer) | 回答プロセス(Answering process) | 事前調査事項(Preliminary research) | NDC | 参考資料(Reference materials) | キーワード(Keywords) | url | |
|---|---|---|---|---|---|---|---|---|
| 1 | 角倉了以(すみのくらりょうい)の墓はなぜ大悲閣(だいひかく)ではなく二尊院にあるのか。 | 二尊院(京都市右京区嵯峨)は角倉家の菩提寺です。【資料1】『寛政重修諸家譜 7』によると,了... | ●まず“二尊院”についての資料を調べる。【資料3】『百寺巡礼 9 京都2』に角倉了以一族の菩... | 個人伝記 (289 8版)寺院.僧職 (185 8版)日本 (291 8版) | 【資料1】『寛政重修諸家譜 7』 (続群書類従完成会 1980) p226~232【資料2】... | 角倉了以二尊院大悲閣千光寺 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... | |
| 2 | 京都の三長者について知りたい。 | 江戸時代初期,角倉・茶屋・後藤を合わせて京の三長者といいました。三家とも,織豊~徳川の時代に... | ●京都のことなので,まずは【資料1】を見る。●当館所蔵の名数関係の資料を当たる。【資料2】●... | 日本史 (210 8版)近畿地方 (216 8版)日本 (291 8版) | 【資料1】『京都大事典』 (佐和隆研編 淡交社 1984) p445 “三長者”,p391~... | 長者角倉家茶屋家後藤家角倉了以角倉素庵茶屋四郎次郎後藤庄三郎後藤徳乗特権商人御用商人政商法華... | http://crd.ndl.go.jp/reference/modules/d3ndlcr... | |
| 3 | 角倉了以について知りたい。 | すみのくらりょうい【角倉了以】 国史大辞典一五五四 - 一六一四安土桃山から江戸時代前期にか... | 日本史 (210 9版) | http://crd.ndl.go.jp/reference/modules/d3ndlcr... | ||||
| 4 | 吉田了意という人物が、水運をひらいたかどうか知りたい。また、京都の川船の呼び名を知りたい。 | 『日本人名大事典』『国史大事典』によると、吉田了意とは角倉了以(天文23(1554)年~慶長... | 1.『日本人名大事典』『国史大事典』『京都高瀬川 角倉了以・素案の遺産』などを調べた。2.京... | 個人伝記 (289 9版) | 『京都高瀬川 角倉了以・素案の遺産』 石田孝喜著 思文閣出版 2005 267p (当館請求... | 吉田了以角倉了以高瀬川高瀬舟川船大堰川 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... | |
| 5 | a)角倉了以についての資料はないか。b)利根川沿革史または河川改修史のような資料はないか。c... | a)角倉了以についての資料 角倉了以に関する直接的な資料は自館に所蔵がないため、 「日本近世... | a)角倉了以についての資料①自館OPACで「角倉了以」をキーワード検索。→ヒットなし。②国立... | a)「日本近世人名辞典」(竹内誠、深井雅海/吉川弘文館/2005)b)「利根川治水史」(栗原... | a)角倉了以b)河川・沿革・改修・歴史c)新田 開発 歴史 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... | ||
| 6 | 1 十石舟・三十石船の成り立ちや歴史を知りたい。2 十石舟の現在の航路を知りたい。 | 1 十石舟・三十石船の成り立ちや歴史 (1) 十石舟について 【資料1】 慶長16年から同... | 当館資料を検索する。・「十石舟」,「三十石船」で【資料5】がヒット。・上記資料より,十石舟・... | 日本 (291 8版)風俗史.民俗誌.民族誌 (382 8版)内水.運河交通 (684... | 【資料1】『京都 高瀬川』(石田孝義著 思文閣出版 2005)【資料2】『日本史大事典 4』... | 十石舟三十石船高瀬舟高瀬川京都市伏見区 | http://crd.ndl.go.jp/reference/modules/d3ndlcr... |
%eb¶
Jupyter notebookは、pandasのデータフレームを自動的に表にして表示してくれて便利なのだが、
- 内容量の多い項目は表示が切れてしまう
- URLを与えてもリンクにならない
という弱点を補うためHTMLオブジェクトにして埋め込む(embed)ためのコマンド %eb を用意した。
Jupyter notebookでは、「_ 」アンダーバーで直前の出力を、アンダーバー+番号で番号の出力(たとえば「_55」でOut[55])を参照できるので、組み合わせて使う。
%eb _
| 質問(Question) | 回答(Answer) | 回答プロセス(Answering process) | 事前調査事項(Preliminary research) | NDC | 参考資料(Reference materials) | キーワード(Keywords) | url | |
|---|---|---|---|---|---|---|---|---|
| 1 | 角倉了以(すみのくらりょうい)の墓はなぜ大悲閣(だいひかく)ではなく二尊院にあるのか。 | 二尊院(京都市右京区嵯峨)は角倉家の菩提寺です。【資料1】『寛政重修諸家譜 7』によると,了以の5代前の祖先である徳春(のりはる)から吉晧(きっこう-了以の甥)に至るまで二尊院が葬地とされています。また【資料2】『角倉素庵』では,従兄弟で岳父である栄可(えいか)の家族や孫の玄紀(はるのり)も二尊院に墓があると記されており,一族の葬地といえます。大悲閣(京都市西京区嵐山)は,正しくは千光寺(せんこうじ)といいます。了以が,河川開削工事に関係した人々の菩提を弔うために再興しました。晩年はこの寺で,二尊院の僧道空(どうくう)に師事し仏門を修めました。死の直後にその遺命で造った,右手に石割斧を持ち工事用の荒綱の円座に座した了以の像が安置されています。※角倉了以(1554~1614)は,安土桃山・江戸初期の京都・嵯峨の豪商です。朱印船で海外交易を行うとともに,国内では河川開墾土木工事を進めました。京都の大堰川・鴨川・高瀬川のほか富士川や天龍川でも通船のための疎通事業を成功させました。角倉家は,初代の徳春から嵯峨に居を定め,了以も嵯峨で生まれ嵯峨で没しました。 | ●まず“二尊院”についての資料を調べる。【資料3】『百寺巡礼 9 京都2』に角倉了以一族の菩提寺,とあり。ただしいつから菩提寺なのかはわからず。●“角倉了以”から調べる。人名事典や了以について記載がある資料を調べるが,墓の場所以上のことはわからず。●“名墓”から調べる。【資料4】『京の名墓探訪』に角倉家の菩提寺,とあり。●“角倉家”から調べる。【資料1】【資料2】のほか【資料5】『角川日本姓氏歴史人物大辞典 26』 “角倉”→本姓は吉田 “吉田”→墓は嵯峨二尊院●“大悲閣”について調べる。【資料6】【資料7】 | 個人伝記 (289 8版)寺院.僧職 (185 8版)日本 (291 8版) | 【資料1】『寛政重修諸家譜 7』 (続群書類従完成会 1980) p226~232【資料2】『角倉素庵』 (林屋辰三郎著 朝日新聞社 1978) p182,235【資料3】『百寺巡礼 9 京都2』 (五木寛之著 淡交社 2004) p71【資料4】『京の名墓探訪』 (高野澄著 淡交社 2004) p75,127【資料5】『角川日本姓氏歴史人物大辞典 26 京都市姓氏歴史人物大辞典』 (角川書店 1997) p714【資料6】『嵯峨誌 平成版』 (嵯峨教育振興会 1998) p337~338【資料7】『京都の歴史を足元からさぐる 嵯峨・嵐山・花園・松尾の巻』 (森浩一著 学生社 2009) p94 | 角倉了以二尊院大悲閣千光寺 | LINK | |
| 2 | 京都の三長者について知りたい。 | 江戸時代初期,角倉・茶屋・後藤を合わせて京の三長者といいました。三家とも,織豊~徳川の時代にかけて,政権との結びつきが強く,政商としての性格を強く持っていました。朱印船貿易では,角倉・茶屋両氏は船を出し,後藤庄三郎は朱印船の帰国後,家康に土産を献上する際に指図したといわれています。また,三家ともに法華宗との関わりを持っており,茶屋・後藤両家は大檀那で,天文法華の乱の際は,町衆方の大将分として活躍しました。角倉家は浄土宗ですが,法華宗の僧である日禛(にっしん)に私有地の小倉山を提供しています。〈角倉家〉医家。土倉。代官職を世襲。本姓は吉田。朱印船貿易では「角倉船」を出しました。通算航海数17回は,朱印船貿易家の中では最多です。了以・与一(素庵)親子は大堰川や高瀬川の開削など,河川土木事業で業績をあげました。〈茶屋家〉呉服商。将軍家呉服御用達。糸割符商人。京都町人頭。本姓は中島。代々「四郎次郎」を名乗る。朱印船貿易では「茶屋船」を出しました。初代四郎次郎清延は本能寺の変の際,家康の伊賀越えを先導し,命の恩人となりました。武人でもあり,家康に付き添って戦に出ること52回という猛者でした。〈後藤家〉金工。御金改役。分銅の製作,分銅改め。金座。小判の検定極印。代々四郎兵衛を通称とした「彫金(または大判座)後藤」と代々庄三郎を名乗る「金座(または小判座)後藤」とがあります。四郎兵衛家は庄三郎家の師家筋に当たります。彫金後藤は祐乗を祖とする,室町時代から続く彫金師の家系です。五代徳乗のとき,秀吉から関東下向の命が下った際,弟子の橋本(一説には山崎とも)庄三郎に後藤姓と光の一字を与えて名代として遣わせました。その後,庄三郎は家康に可愛がられ,外国人から「家康の財務長官」と呼ばれるほどになりました。 | ●京都のことなので,まずは【資料1】を見る。●当館所蔵の名数関係の資料を当たる。【資料2】●【資料1】【資料2】より,近世に活躍した人物であることが分かったので【資料3】を見る。●“角倉了以”,“後藤庄三郎”,“茶屋四郎次郎”,“豪商”,“町衆”をキーワードに調査する。【資料4】~【資料15】●【資料10】より,“法華宗”に関係があることが分かったので,これをキーワードに調査する。【資料16】●【資料16】の参考文献より【資料17】●京都の歴史から調査する。【資料18】 | 日本史 (210 8版)近畿地方 (216 8版)日本 (291 8版) | 【資料1】『京都大事典』 (佐和隆研編 淡交社 1984) p445 “三長者”,p391~392 “後藤家”“後藤庄三郎”“後藤徳乗”,p537~538 “角倉家”“角倉素庵”“角倉了以”,p618~619 “茶屋家”“茶屋四郎次郎”【資料2】『都の数えうた』 (京都新聞社編集・発行 1992) p66~67 “三長者”【資料3】『日本近世人名辞典』(竹内誠編 吉川弘文館 2005) p373~375 “後藤庄三郎”“後藤四郎兵衛”“後藤徳乗”,p512~513 “角倉素庵”“角倉了以”,p614~615 “茶屋四郎次郎”【資料4】『四条 vol.5』 (コーディネイトルーム・ノウハウ編 四条繁栄会商店街振興組合 1992) p21~24 “京都商人列伝―後藤庄三郎”【資料5】『四条 vol.6』 (コーディネイトルーム・ノウハウ編 四条繁栄会商店街振興組合 1993) p21~24 “京都商人列伝―茶屋四郎次郎”【資料6】『四条 vol.7』 (コーディネイトルーム・ノウハウ編 四条繁栄会商店街振興組合 1993) p21~24 “京都商人列伝―角倉了以”【資料7】『持丸長者 幕末・維新篇』 (広瀬隆著 ダイヤモンド社 2007) p43~48 “金座の後藤四郎兵衛と後藤庄三郎”,p56~57 “系図1 本阿弥家を中心とする金座銀座・芸術家の閨閥”,p58~60 “京の三長者・角倉了以”,p60~62 “京の三長者・茶屋四郎次郎”【資料8】『京都高瀬川 角倉了以・素庵の遺産』 (石田孝喜著 思文閣出版 2005)【資料9】『刀装金工後藤家十七代』 (島田貞良著 雄山閣出版 1973)【資料10】『町衆』 (林屋辰三郎著 中央公論社 1964) p172~177 “旦那の群像”【資料11】『京都新聞 2002年5月 6日朝刊』 17面 “京近江の豪商列伝1 角倉了以・素庵 上”【資料12】『京都新聞 2002年5月13日朝刊』 13面 “京近江の豪商列伝2 角倉了以・素庵 中”【資料13】『京都新聞 2002年5月20日朝刊』 13面 “京近江の豪商列伝3 角倉了以・素庵 下”【資料14】『京都新聞 2002年5月27日朝刊』 11面 “京近江の豪商列伝4 後藤徳乗・庄三郎”【資料15】『京都新聞 2002年6月 3日朝刊』 13面 “京近江の豪商列伝5 茶屋四郎次郎”【資料16】『法華文化の展開』 (藤井学著 法臧館 2002) p193~223 “日奥”,p335~366 “近世初頭における京都町衆の法華信仰”【資料17】『中世文化の基調』 (林屋辰三郎著 東京大学出版会 1958) p258~285 “上層町衆の系譜―京都に於ける三長者を中心に―”【資料18】『京都の歴史 第4巻 桃山の開花』 (京都市 京都市史編さん所 1979) p5,p152~156,p396~456,p532~561 | 長者角倉家茶屋家後藤家角倉了以角倉素庵茶屋四郎次郎後藤庄三郎後藤徳乗特権商人御用商人政商法華宗町衆豪商朱印船貿易 | LINK | |
| 3 | 角倉了以について知りたい。 | すみのくらりょうい【角倉了以】 国史大辞典一五五四 - 一六一四安土桃山から江戸時代前期にかけての朱印船貿易ならびに河川土木事業家。・・・[参考文献]『大日本史料』一二ノ一四 慶長十九年七月十二日条林屋辰三郎『角倉了以とその子』角倉了以(すみのくらりょうい) (1554―1614) Yahoo!百科事典[日本大百科全書(小学館)] http://100.yahoo.co.jp/detail/%E8%A7%92%E5%80%89%E4%BA%86%E4%BB%A5/ (2012/10/31確認)参考文献林屋辰三郎著『角倉了以とその子』(1944・星野書店)すみのくら‐りょうい〔‐レウイ〕【角倉了以】 大辞泉[1554~1614]安土桃山から江戸初期の豪商。京都の人。名は光好。豊臣秀吉・徳川家康の朱印状を得て、安南・東京(トンキン)方面との貿易で巨利を得た。また、大堰(おおい)川・富士川・天竜川・高瀬川などの水路の開発に尽力。角倉了以【すみのくら・りょうい】 コトバンク http://kotobank.jp/word/%E8%A7%92%E5%80%89%E4%BA%86%E4%BB%A5 (2012/10/31確認)<参考文献>「角倉文書」(『大日本史料』12編14所収),「角倉文書」(京都角倉平吉氏蔵),「角倉文書」(高輪美術館蔵),林屋辰三郎『角倉了以とその子』,中田易直「近世初頭の大事業家角倉了以」(『金融ジャーナル』1974年8月号)京都高瀬川 : 角倉了以・素庵の遺産 / 石田孝喜著 京都 : 思文閣出版 , 2005 4784212531 https://opac.clib.kindai.ac.jp/opac/opac_details.cgi?lang=0&amode=11&place=&bibid=BT00092023&key=B135168829222182&start=1&srmode=0 (2012/10/31確認) | 日本史 (210 9版) | LINK | ||||
| 4 | 吉田了意という人物が、水運をひらいたかどうか知りたい。また、京都の川船の呼び名を知りたい。 | 『日本人名大事典』『国史大事典』によると、吉田了意とは角倉了以(天文23(1554)年~慶長19(1614)年)のことで、朱印船貿易で活躍した豪商、京都の大堰川(保津川)や高瀬川の水運をひらき、京都以外では富士川、天竜川の開削を行なった。また、『京都高瀬川』『川船』によると、京都では高瀬川を就航する川船のことを「高瀬船」と呼び、森鴎外の小説『高瀬舟』にも登場する。高瀬川の名称は、了以がひらいた川に高瀬船が航行したことに由来する。なお、高瀬とは川の浅瀬のことで、高瀬船とは、浅瀬を運航するため船底を平たく浅くした小型船で、船首が高く船体の幅が広い舟のことで、大堰川の川船も高瀬船であるとされる。*資料により「船」「舟」の記述があるが、固有名詞を除き「船」に統一した。 | 1.『日本人名大事典』『国史大事典』『京都高瀬川 角倉了以・素案の遺産』などを調べた。2.京都府立総合資料館・京都府立図書館の蔵書検索システムで、キーワード「高瀬川」「角倉」などを検索した。 | 個人伝記 (289 9版) | 『京都高瀬川 角倉了以・素案の遺産』 石田孝喜著 思文閣出版 2005 267p (当館請求記号K1/517.6/I72)『川船 大堰川の舟運と船大工』 亀岡市文化資料館編刊 2007 47p (当館請求記号K1.8/684.02/Ka35)『角倉了以とその子』 林屋辰三郎著 星野書店 1944 201p (当館請求記号K1/289.1/Su63) | 吉田了以角倉了以高瀬川高瀬舟川船大堰川 | LINK | |
| 5 | a)角倉了以についての資料はないか。b)利根川沿革史または河川改修史のような資料はないか。c)江戸時代の新田開発史のような資料はないか。 | a)角倉了以についての資料 角倉了以に関する直接的な資料は自館に所蔵がないため、 「日本近世人名辞典」、「朝日日本歴史人物事典」の“角倉了以”の項(近世:p513/朝日:p897)を提示。b)利根川沿革史または河川改修史のような資料 「利根川治水史」(栗原良輔/山愛書院/1997) 「利根川の洪水」(利根川研究会/山海堂/1995)c)江戸時代の新田開発史のような資料 「飯沼新田開発」(長命豊/崙書房/) 「天保期の印旛沼堀割普請」(千葉市史編纂委員会/千葉市/1998) 「手賀沼周辺の水害」(中尾正己/我孫子市教育委員会/1986) 「手賀沼の今昔」(星野七郎/崙書房/1987) | a)角倉了以についての資料①自館OPACで「角倉了以」をキーワード検索。→ヒットなし。②国立国会図書館提供の“リサーチ・ナビ”で「角倉了以」をキーワード検索。→本は79件ヒット。質問者に検索結果のみ提示。③人名辞典・人物事典をあたる。→「日本近世人名辞典」、「朝日日本歴史人物事典」の角倉了以の項を提示。b)利根川沿革史または河川改修史のような資料自館郷土資料コーナーをブラウジング。→「利根川治水史」「利根川の洪水」を提示。c)江戸時代の新田開発史のような資料①自館OPACで「江戸時代 新田 開発」をキーワード検索。→18件ヒットするが、それらしいものは「飯沼新田開発」のみであった。②郷土資料コーナーをブラウジング。→「天保期の印旛沼堀割普請」 「手賀沼周辺の水害」 「手賀沼の今昔」を提示。 | a)「日本近世人名辞典」(竹内誠、深井雅海/吉川弘文館/2005)b)「利根川治水史」(栗原良輔/山愛書院/1997)c)「天保期の印旛沼堀割普請」(千葉市史編纂委員会/千葉市/1998) | a)角倉了以b)河川・沿革・改修・歴史c)新田 開発 歴史 | LINK | ||
| 6 | 1 十石舟・三十石船の成り立ちや歴史を知りたい。2 十石舟の現在の航路を知りたい。 | 1 十石舟・三十石船の成り立ちや歴史 (1) 十石舟について 【資料1】 慶長16年から同年19年にかけて角倉了以が開削した高瀬川(鴨川の水を利用した京都二条と 伏見を結ぶ運河)で用いられた。大阪から淀川をさかのぼってきた二十石船・三十石船の積荷を, 高瀬川と宇治川派流との合流地点である伏見で高瀬舟に積み替え,二条まで運んだ。 明治3年,「早船」と呼ばれる京~伏見間を往復する客を運ぶ舟としても用いられる。 明治5年,京都博覧会の開催時に,淀川・高瀬川に見物客のための早船が出現。淀川早船(三十石船)が 夜間に伏見~淀川間を航行。 明治後期に,琵琶湖疏水の完成,市電の開通にともない高瀬舟は衰退。 大正9年に約300年の歴史に幕が閉じられた。 【資料5】 p20 現在は平成10年から観光用に運航を始めた。 【資料1】 p200 高瀬舟についての記述あり。p211~212 十石積舟の略図と明細(図111)あり。 【資料8】 p709 『和漢船用集』に,京都の高瀬舟についての記述と,高瀬舟が川を下っている絵が 載っていると記述あり。 (2) 三十石船について 【資料5】 p20 江戸時代初期,伏見と大坂を結ぶ交通機関として宇治川と淀川で運航を開始。最盛期には1日に 320便近くが往復した。明治時代に,鉄道の発達により廃止。現在は,旅館が運航する観光船で宇治川, 桂川,木津川の合流近くの淀までを往復している。 【資料4】 p5 伏見は,高瀬川の開削により,高瀬舟と淀川の過書船との発着地点となり,京都大阪をつなぐ中継 港的性格を帯びることとなった。p6 「淀川の舟運」の挿絵あり。p34 三十石船についての記述あり。 【資料3】 海船・川船を問わず米三十石相当の積載能力をもつ船の総称。通常は,近世淀川水運を担った過書座 支配下の過書座船中の人乗せ三十石船または早船三十石と よぶ乗合船をいう。 【資料8】 p603 過書船について記述あり。 p604 図14-1,図14-2,図14-3 家書船の系譜となる鎌倉時代~ 戦国時代~江戸時代の船図あり。 p610 表14-2 過書船はいくつかの船の呼称のひとつで,用途や地域 によって呼称が変わる。 2 十石舟の現在の航路 月桂冠大倉記念館裏乗船場発→三栖閘門下船(見学)→乗船→月桂冠大倉記念館裏乗船場着。 (参考) 三十石船の現在の航路 寺田屋浜乗船場 発→三栖閘門下船(見学)→乗船→寺田屋浜乗船場 着。 【資料7】 表紙写真に,坂本龍馬とお龍のブロンズ像横の三十石船の乗船場が使われている。 | 当館資料を検索する。・「十石舟」,「三十石船」で【資料5】がヒット。・上記資料より,十石舟・三十石舟ともに高瀬川に関係する“ふね”であることから,「高瀬川」を検索, 【資料1】【資料9】がヒット。「高瀬川」「高瀬舟」「十石舟」「三十石船」について,『日本史大事典』を調べる。・「十石船」の記述は見つからなかった。・【資料2】 p633に「高瀬川」「高瀬舟」の記述と参考文献に【資料8】が掲載されていた。・【資料3】 p543に「三十石船」の記述が見つかった。インターネット検索サイトで,キーワード「十石舟」「伏見 三十石船」を検索する。・まちづくり会社伏見夢工房がヒット。 http://www.kyoto-fushimi.com/ (2012/6/25最終確認)・航路や運航スケジュール。 http://kyoto-fushimi-kanko.jp/news19.html (2012/6/25最終確認)。 なお,十石舟三十舟事業は2012年春の運行からNPO法人伏見観光協会に移管された(「三十石舟」の 表記は,HPのママ)。・同ページのインデックスから,“伏見について”に伏見略年表,“伏見小話”に淀川三十石船の記述あり。 http://kyoto-fushimi-kanko.jp/index.html (2012/6/25最終確認)。 次の資料にも同様の記述あり。1(1) 【資料1】 p226 「第6章 高瀬舟運の推移」,巻末に東高瀬川の実測図あり。 【資料8】 p691 「第15章 京都大堰川の開削・通船事業と川船」。 (2) 【資料8】 p631~632 「三-1 伏見船」に,三十石船の繁栄と衰退の記載あり。 【資料9】 上巻p29 「高瀬舟と船頭」,下巻p54 「伏見と高瀬舟」に角倉了以によって開削された当時の 様子の記述あり。 【資料10】 p98 「十石舟」2 【資料5】 p20 コースの記述,p32 周辺地図。 【資料6】 伏見散策マップ 【資料11】 p5~6 地図,p18 十石舟乗船場の説明 | 日本 (291 8版)風俗史.民俗誌.民族誌 (382 8版)内水.運河交通 (684 8版) | 【資料1】『京都 高瀬川』(石田孝義著 思文閣出版 2005)【資料2】『日本史大事典 4』(平凡社 1993)【資料3】『日本史大事典 6』(平凡社 1994)【資料4】『京・伏見歴史の旅』(山本正嗣著 山川出版社 2003)【資料5】『ヴィジュアル百科 週刊京都を歩く 第46号 伏見②』(講談社 2004)【資料6】パンフレット「十石舟・三十石船の旅」(NPO法人伏見観光協会)【資料7】『京都THE FUSHIMI 2012年5月号』(伏見プランニングセンター)【資料8】『近世日本の川船研究 下』(川名登著 日本経済評論社 2005)【資料9】『高瀬川 上・下』(田中緑紅著 京都を語る会 1959)【資料10】『京都水ものがたり』(平野圭祐著 淡交社 2003)【資料11】『京の道探検ブック 3 伏見編』(国土交通省近畿地方整備局 京都国道事務所 2006) | 十石舟三十石船高瀬舟高瀬川京都市伏見区 | LINK |
%dictj¶
キーワードについて手持ちの辞書(EPWING)とネット上の日本語事典をまとめて検索し、記述の短い順から並べて表示する。
短い順に並べるのは、要点:要するに何なのかを先にし、詳細情報を後に回すためである。
事典を引けば決着が着くといった僥倖は、実際の探しものでは、ほとんどないが、文献を探し評価するのに必要な前提知識を押さえておくためには、事典引きを飛ばすのは推奨されない。
%dictj t
. . . . . . . . . . . . . . . . . . . . . . . . . . .
| item_title | dict_name | description | des_size | url | |
|---|---|---|---|---|---|
| 1 | すみのくらりょうい【角倉了以】 | 大辞林 第三版 | (1554~1614)安土桃山時代から江戸初期の豪商。京都の生まれ。豊臣秀吉に朱印状を得て安... | 85 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 2 | 角倉了以(商人) | 参考調査便覧 | 角倉了以(商人) \n【3】日本貿易人の系譜 宮本又次他 有斐閣1980\n\n\n | 92 | (epwing) |
| 3 | 角倉了以【すみのくらりょうい】 | 百科事典マイペディア | 安土桃山時代から江戸初期にかけての京都の豪商,海外貿易家。本姓吉田,名は光好(みつよし)。1... | 110 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 4 | すみのくら‐りょうい〔‐レウイ〕【角倉了以】 | デジタル大辞泉 | [1554~1614]安土桃山から江戸初期の豪商。京都の人。名は光好。豊臣秀吉・徳川家康の朱... | 111 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 5 | 【大堰川】より | 世界大百科事典内の角倉了以の言及 | …織豊期になると材木の需要が急増し,豊臣秀吉は1588年(天正16)宇津,保津,山本などの筏... | 184 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 6 | 角倉了以すみのくらりょうい | ブリタニカ国際大百科事典 小項目事典 | [生]天文23(1554).京都[没]慶長19(1614).7.12.京都安土桃山時代の海外... | 184 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 7 | 角倉了以 すみのくら-りょうい | デジタル版 日本人名大辞典+Plus | 1554-1614 織豊-江戸時代前期の豪商。天文(てんぶん)23年生まれ。吉田宗桂(そうけ... | 203 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 8 | すみのくら-りょうい ―レウイ 【角倉了以】 | 大辞林 | すみのくら-りょうい ―レウイ 【角倉了以】\n(1554-1614) 安土桃山時代から江戸... | 293 | (epwing) |
| 9 | すみのくらりょうい【角倉了以】 | 世界大百科事典 第2版 | 1554‐1614(天文23‐慶長19)安土桃山時代の海外貿易商で,河川開発家。近江国愛知郡... | 306 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 10 | すみのくら‐りょうい【角倉了以】(‥レウイ) | 国語大辞典 | すみのくら‐りょうい【角倉了以】(‥レウイ)\n安土桃山・江戸初期の貿易家、土木事業家。名は... | 337 | (epwing) |
| 11 | すみのくら‐りょうい【角倉了以】‐レウイ | 大辞泉 | すみのくら‐りょうい【角倉了以】‐レウイ\n[一五五四~一六一四]安土桃山から江戸初期の豪商... | 396 | (epwing) |
| 12 | すみのくら‐りょうい【角倉了以】‥レウ‥ | 広辞苑 | すみのくら‐りょうい【角倉了以】‥レウ‥\n安土桃山・江戸初期の豪商・土木家。名は光好。洛西... | 449 | (epwing) |
| 13 | 角倉了以 | Wikipedia 日本語 | 角倉 了以(すみのくら りょうい、天文23年(1554年) - 慶長19年7月12日(161... | 596 | https://ja.wikipedia.org/wiki/%E8%A7%92%E5%80%... |
| 14 | 角倉了以【すみのくらりょうい】 | 岩波日本史辞典 | 角倉了以【すみのくらりょうい】\n1554‐1614(天文23‐慶長19.7.12) 安土桃... | 627 | (epwing) |
| 15 | 角倉了以すみのくらりょうい(1554―1614) | 日本大百科全書(ニッポニカ) | 安土(あづち)桃山時代の貿易家、土木事業家。本姓は吉田氏、幼名与七、名は光好。吉田氏は近江(... | 787 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 16 | 角倉了以 すみのくらりょうい | 人物レファレンス事典 | 角倉了以 すみのくらりょうい\n天文23(1554)年~慶長19(1614)年7月12日 ... | 861 | (epwing) |
| 17 | 角倉了以 | ブリタニカ小項目版 | 角倉了以\nすみのくらりょうい\n[生] 天文23(1554).京都\n[没] 慶長19(1... | 869 | (epwing) |
| 18 | 角倉了以 | 朝日日本歴史人物事典 | 没年:慶長19.7.12(1614.8.17)生年:天文23(1554)近世初頭の京都の豪商... | 878 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 19 | 角倉了以 | 世界大百科事典 | 角倉了以\nすみのくらりょうい\n1554‐1614(天文23‐慶長19)\n⇒<関連項目|... | 1379 | (epwing) |
| 20 | 角倉了以 | 日本大百科全書 | 角倉了以\nすみのくらりょうい\n(1554―1614)安土(あづち)桃山時代の貿易家、土木... | 2261 | (epwing) |
%selectindex¶
MonkeyBenchでのライブラリリサーチは、〈コマンドによる働きがけ〉と〈それに対する反応=検索結果〉の繰り返しである。 検索結果を再利用するために、検索結果の絞込のコマンドが用意されている。
%selectindexは、与えたデータフレームから、index番号で指定された行を抜き出すためのコマンド
例:直近の結果(データフレーム)から1,4〜7,10行目を抜き出す %selectcol _94, 1,4:7,10
%selectindex _,13:20
| item_title | dict_name | description | des_size | url | |
|---|---|---|---|---|---|
| 13 | 角倉了以 | Wikipedia 日本語 | 角倉 了以(すみのくら りょうい、天文23年(1554年) - 慶長19年7月12日(161... | 596 | https://ja.wikipedia.org/wiki/%E8%A7%92%E5%80%... |
| 14 | 角倉了以【すみのくらりょうい】 | 岩波日本史辞典 | 角倉了以【すみのくらりょうい】\n1554‐1614(天文23‐慶長19.7.12) 安土桃... | 627 | (epwing) |
| 15 | 角倉了以すみのくらりょうい(1554―1614) | 日本大百科全書(ニッポニカ) | 安土(あづち)桃山時代の貿易家、土木事業家。本姓は吉田氏、幼名与七、名は光好。吉田氏は近江(... | 787 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 16 | 角倉了以 すみのくらりょうい | 人物レファレンス事典 | 角倉了以 すみのくらりょうい\n天文23(1554)年~慶長19(1614)年7月12日 ... | 861 | (epwing) |
| 17 | 角倉了以 | ブリタニカ小項目版 | 角倉了以\nすみのくらりょうい\n[生] 天文23(1554).京都\n[没] 慶長19(1... | 869 | (epwing) |
| 18 | 角倉了以 | 朝日日本歴史人物事典 | 没年:慶長19.7.12(1614.8.17)生年:天文23(1554)近世初頭の京都の豪商... | 878 | https://kotobank.jp/word/%E8%A7%92%E5%80%89%E4... |
| 19 | 角倉了以 | 世界大百科事典 | 角倉了以\nすみのくらりょうい\n1554‐1614(天文23‐慶長19)\n⇒<関連項目|... | 1379 | (epwing) |
| 20 | 角倉了以 | 日本大百科全書 | 角倉了以\nすみのくらりょうい\n(1554―1614)安土(あづち)桃山時代の貿易家、土木... | 2261 | (epwing) |
%eb _
| item_title | dict_name | description | des_size | url | |
|---|---|---|---|---|---|
| 1 | 角倉了以 | Wikipedia 日本語 | 角倉 了以(すみのくら りょうい、天文23年(1554年) - 慶長19年7月12日(1614年8月17日))は、戦国期の京都の豪商。 朱印船貿易の開始とともに安南国との貿易を行い、山城(京都)の大堰川、高瀬川を私財を投じて開削した。また幕命により富士川、天竜川等の開削を行った。地元京都では商人と言うより琵琶湖疏水の設計者である田辺朔郎と共に「水運の父」として有名である。 長男に角倉素庵、弟に吉田宗恂。吉田光由は一族にあたる。墓所は京都市嵯峨野の二尊院。 == 家系 == 角倉家の本姓は「吉田氏」。佐々木氏の分家であるという。もともとは近江国犬上郡吉田村出身とされ、室町時代中期に上洛し室町幕府お抱えの医者としてつとめた。その後、医業で得た財を元に土倉を営むようになる。了以の祖父・吉田宗忠は土倉業は長男に継がせ、次男に医者を継がせた。この次男・吉田宗桂が了以の実父である。 角倉家は茶屋四郎次郎の「茶屋家」、後藤庄三郎の「後藤家」とともに「京の三長者」といわれる権勢を誇っていたが、他の2家が徳川家康に接近することで急成長したのに対し、角倉家はそれ以前より成功していた商人であったところが異なる。 「角倉」は運営していた土倉の名前の一つから取られた物である。 == 関連項目 == 高瀬川二条苑 == 外部リンク == 高瀬川物語 - 角倉了以 大悲閣公式ホームページ | 596 | LINK |
| 2 | 角倉了以【すみのくらりょうい】 | 岩波日本史辞典 | 角倉了以【すみのくらりょうい】 1554‐1614(天文23‐慶長19.7.12) 安土桃山・江戸初期の京都の豪商,<[@hE542]朱印船貿易|2158:1366>家。医者<[@hE542]吉田宗桂|4486:836>の長男。幼名与七。諱は光好。1572(元亀3)土倉どそう経営を継ぎ,1603‐11(慶長8‐16)に朱印船(角倉船)で安南・東京トンキン貿易に従事する一方,06年嵯峨の<[@hE542]大堰川|565:1576>,翌年<[@hE542]富士川|3814:1700>の疎通や<[@hE542]高瀬川|2770:442>の運河開削(11‐14年)を行なった。子の素庵,孫の玄紀らも貿易や河川支配に活躍。 | 627 | (epwing) |
| 3 | 角倉了以すみのくらりょうい(1554―1614) | 日本大百科全書(ニッポニカ) | 安土(あづち)桃山時代の貿易家、土木事業家。本姓は吉田氏、幼名与七、名は光好。吉田氏は近江(おうみ)佐々木氏の流といい、了以は角倉家5代とされる。角倉家は応永(おうえい)(1394~1428)のころ現れた徳春(とくしゅん)を初代とし、徳春およびその子宗臨(そうりん)はともに医術に長じた。了以の祖父宗忠(そうちゅう)は、1544年(天文13)亀屋五位女(かめやごいめ)から洛中帯座座頭職(らくちゅうおびざざとうしき)ならびに公用代官職を獲得し、またこのころ嵯峨(さが)大覚寺境内に土倉(どそう)(高利貸)業を始め、嵯峨角倉は豪商としても著名になった。了以の父宗桂(そうけい)(意庵(いあん))は遣明(けんみん)使節策彦周良(さくげんしゅうりょう)に従って入明(にゅうみん)し、医者としても高名であった。しかし了以は医業を継がず、算数・地理を学び、当時勃興(ぼっこう)してきた海外通商および国内の建設諸事業に進出した。すなわち、徳川家康の知遇を得て1603年(慶長8)以後10年まで数回にわたり異国渡海の朱印状の交付を受け、安南(アンナン)・東京(トンキン)地方に貿易船を派遣し、それ以後は子の玄之(はるゆき)(素庵(そあん))が貿易事業を継承した。土木事業では、05年に丹波(たんば)・山城(やましろ)を結ぶ大堰(おおい)川の疎通を計画、翌年これを完成したほか、幕命により富士川、天竜川の疎通を行い、京都では高瀬川を開削(かいさく)した。この結果、角倉家はこれら河川の通船支配権を獲得し、また搬出材木によって上方(かみがた)の有力材木商となるなど多大の経済的利益も得た。晩年、琵琶(びわ)湖の疎水計画をたて、勢多(せた)―宇治間の舟行と琵琶湖水位の低下による新田開発を図ったが実現には至らなかったという。[村井益男]『林屋辰三郎著『角倉了以とその子』(1944・星野書店)』 | 787 | LINK |
| 4 | 角倉了以 すみのくらりょうい | 人物レファレンス事典 | 角倉了以 すみのくらりょうい 天文23(1554)年~慶長19(1614)年7月12日 別名=吉田了以(よしだりょうい) 安土桃山時代・江戸時代前期、京都の豪商。河川開墾土木工事の大家、朱印船貿易家。 【掲載事典】 ◎朝日日本歴史人物事典 【没】慶長19年7月12日(1614年8月17日) ◎国史大辞典 ◎コンサイス日本人名事典 改訂版 ◎茶道人物辞典 ◎新潮日本人名辞典 ◎人物書誌索引78/91 ◎(新版)世界人名辞典 日本編〈増補版〉 ◎世界大百科事典 ◎世界伝記大事典 日本・朝鮮・中国編 ◎戦国人名事典 ◎戦国人名辞典 増訂版 【生】1555年 ◎大日本百科事典 ◎大百科事典 ◎日本史大事典 ◎日本重要人物辞典 新訂版 ◎日本人名大事典 ◎日本大百科全書 | 861 | (epwing) |
| 5 | 角倉了以 | ブリタニカ小項目版 | 角倉了以 すみのくらりょうい [生] 天文23(1554).京都 [没] 慶長19(1614).7.12. 京都 安土桃山時代の海外貿易家,土木事業家。幼名は与七,のち了以。諱は光好。京都嵯峨の土倉吉田家の出。文禄1 (1592) 年豊臣秀吉から,慶長9 (1604) 年以降は徳川氏から朱印状を与えられ安南国トンキン (東京) に朱印船 (角倉船と呼ばれた) を派遣し巨利を得た。また治水事業,河川開発の技術にも長じ,同 11年の大堰川 (丹波−山城) の浚渫,疎通をはじめとして,富士川 (駿河岩淵−甲府) ,天竜川 (遠江掛塚−信濃諏訪) ,高瀬川 (京都二条−伏見) などの開削を行い,これらの河川を利用して材木その他の物質を搬出し資産をなした。 →5-234 京都, 10-192 角倉了以 | 869 | (epwing) |
| 6 | 角倉了以 | 朝日日本歴史人物事典 | 没年:慶長19.7.12(1614.8.17)生年:天文23(1554)近世初頭の京都の豪商,河川開墾土木工事の大家,朱印船貿易家。吉田宗桂と中村氏の娘の長男。本姓吉田,名を与七,諱は光好。先祖は室町幕府に医者として仕えた。また嵯峨の土倉として金融業を営み,屋号を角倉と称した。父宗桂も医者として名高く,勘合貿易に従事し,薬種類の購入など行った。了以は豊臣秀吉政権下では家業に協力していたが,のち医者は次弟の宗恂にやらせ,慶長5(1600)年ごろより時代をみて徳川家康に近づいた。豪放闊達な人物で,同8年ごろより安南国東京(インドシナ半島)との朱印船貿易に従事し,長男与一(素庵)らの協力を得て毎年のように実施し,日本を代表する使節でもあった。同14年の帰途海難にあい,犠牲者を出してから,貿易は与一に譲っている。了以は父の科学者的素質を受け,数学や地理に明るく,土木工事の技術に進んだ力量を持っていた。同9年丹波から京都に米穀や材木などを人馬で運送している労力をみて,大堰川の開疏を行い,高瀬船による河川交通によって,物資の流通を自由にすることを考え,幕府の許可を得て同10年,同11年に開削工事を自ら陣頭に立って完遂し,その河川運航料や倉庫料の徴収が特許され,これが角倉の収入となった。次いで幕府は同11年了以に富士川の疏通を命じ,翌年工事が達成された。同12年天竜川の開疏を命じられているが,これは難工事で成功していない。同16年,京都二条から伏見に至る運河を計画,淀川に接続させる高瀬川の開鑿を,自費で困難な条件を克服して完成し,京都の町に木材,食糧,薪炭などの物資が運送された。幕府は高瀬川の通航料を徴収し,幕府と角倉の収益とし,角倉は代々淀川の河川交通や高瀬川を支配した。高瀬川の完成直後に病没。墓地は嵯峨二尊院。「角倉文書」(『大日本史料』12編14所収),「角倉文書」(京都角倉吾郎氏蔵),「角倉文書」(高輪美術館蔵),林屋辰三郎『角倉了以とその子』,中田易直「近世初頭の大事業家角倉了以」(『金融ジャーナル』1974年8月号)(中田易直) | 878 | LINK |
| 7 | 角倉了以 | 世界大百科事典 | 角倉了以 すみのくらりょうい 1554‐1614(天文23‐慶長19) ⇒<関連項目|84157:72> 安土桃山時代の海外貿易商で,河川開発家。近江国愛知郡吉田郷を出自とし,吉田が本姓。祖父宗忠が洛西嵯峨で土倉営業に成功し,屋号を角倉と称する豪商となった。了以の父宗桂は,吉田家の家業であった医術にすぐれ,策彦(さくげん)周良に従って明(中国)に渡り名声を高めた。了以は宗桂の長子で,通称与七,諱(いみな)は光好,了以は法号である。性格は豪放不羇(ふき)で海外雄飛を志し,また土木建設にも興味をもった。1592年(文禄1),豊臣秀吉から朱印状を得て安南国に角倉船を派遣したとも伝え,弟宗恂や息子<角倉素庵|36101:1248>の協力を得て,1603年(慶長8)以降海外貿易に従事したのは明らかである。全国諸河川の通船のための開削工事も積極的に行った。06年着工の大堰(おおい)川開削が最初で,辛苦の末に丹波と京都間の通船に成功した。以後幕命をうけて07年には富士川,翌年には天竜川の疏通にも取り組んだ。京都では,京都経済の大動脈となった高瀬川の舟運を開いた。 <鎌田 道隆|77516:538> | 1379 | (epwing) |
| 8 | 角倉了以 | 日本大百科全書 | 角倉了以 すみのくらりょうい (1554―1614)安土(あづち)桃山時代の貿易家、土木事業家。本姓は吉田氏、幼名与七、名は光好。吉田氏は近江(おうみ)佐々木氏の流といい、了以は角倉家5代とされる。角倉家は応永(おうえい)(1394~1428)のころ現れた徳春(とくしゅん)を初代とし、徳春およびその子宗臨(そうりん)はともに医術に長じた。了以の祖父宗忠(そうちゅう)は、1544年(天文13)亀屋五位女(かめやごいめ)から洛中帯座座頭職(らくちゅうおびざざとうしき)ならびに公用代官職を獲得し、またこのころ嵯峨(さが)大覚寺境内に土倉(どそう)(高利貸)業を始め、嵯峨角倉は豪商としても著名になった。了以の父宗桂(そうけい)(意庵(いあん))は遣明(けんみん)使節策彦周良(さくげんしゅうりょう)に従って入明(にゅうみん)し、医者としても高名であった。しかし了以は医業を継がず、算数・地理を学び、当時勃興(ぼっこう)してきた海外通商および国内の建設諸事業に進出した。すなわち、徳川家康の知遇を得て1603年(慶長8)以後10年まで数回にわたり異国渡海の朱印状の交付を受け、安南(アンナン)・東京(トンキン)地方に貿易船を派遣し、それ以後は子の玄之(はるゆき)(素庵(そあん))が貿易事業を継承した。土木事業では、05年に丹波(たんば)・山城(やましろ)を結ぶ大堰(おおい)川の疎通を計画、翌年これを完成したほか、幕命により富士川、天竜川の疎通を行い、京都では高瀬川を開削(かいさく)した。この結果、角倉家はこれら河川の通船支配権を獲得し、また搬出材木によって上方(かみがた)の有力材木商となるなど多大の経済的利益も得た。晩年、琵琶(びわ)湖の疎水計画をたて、勢多(せた)―宇治間の舟行と琵琶湖水位の低下による新田開発を図ったが実現には至らなかったという。〈村井益男〉 【本】林屋辰三郎著『角倉了以とその子』(1944・星野書店) | 2261 | (epwing) |
%webcat¶
%webcatは、webcat plus minusを使って書籍等を検索して、結果をデータフレームにするコマンド。 国会図書館サーチを検索できる%ndlの方が書籍、雑誌記事だけでなく、デジタル資料やレファレンス事例などを含めて検索でき網羅的だが上限500件の制限がある。
%webcat 角倉了以
. . . . . . . . .
| title | description | url | |
|---|---|---|---|
| 1 | 常在戦場 | 火坂雅志 著, 文藝春秋, 2015.5, 355p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 2 | 角倉一族とその時代 | 森洋久 編, 思文閣, 2015.7, 617,5p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 3 | 曳舟の道 | 濱岡三太郎 著, 幻冬舎ルネッサンス, 2013.8, 245p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 4 | 徳川三百年を支えた豪商の「才覚」 | 童門冬二 著, 角川マガジンズ : KADOKAWA, 2013.9, 239p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 5 | 角倉了以の世界 | 宮田章 著, 大成出版社, 2013.4, 163p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 6 | 常在戦場 | 火坂雅志 著, 文藝春秋, 2013.3, 319p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 7 | 森鷗外 : 永遠の問いかけ | 杉本完治 著, 新典社, 2012.9, 298p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 8 | 復興の日本史 : いかにして度重なる災害や危機を乗り越えてきたか | 河合敦 著, 祥伝社, 2012.6, 278p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 9 | 武田信玄織田信長豊臣秀吉 | 松下忠實 他著 ; 子ども文化研究所 監修, いずみ書房, 2012.6, 改訂新版., 6... | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 10 | 角倉了以と富士川 | 淡路一朗 著, 山梨ふるさと文庫, 2011.4, 373p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 11 | 石造文化財 3 (坂詰秀一先生地域文化功労賞受賞記念号) | 石造文化財調査研究所 編, 石造文化財調査研究所 : 雄山閣, 2011.5, 3 (坂詰秀... | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 12 | この者、只者にあらず : 角倉了以 | 中田有紀子 著, 致知出版社, 2009.12, 303p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 13 | 人物で知る日本の国土史 | 緒方英樹 著, オーム社, 2008.8, 207p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 14 | 江戸の未来人列伝 : 47都道府県郷土の偉人たち | 泉秀樹 著, 祥伝社, 2008.9, 452p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 15 | 京・嵯峨嵐山の伝承を歩く | 山嵜泰正 著, ふたば書房, 2008.7, 206p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 16 | 江戸商人・成功の法則八十手 | 羽生道英 著, PHP研究所, 2007.12, 300p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 17 | 中世民衆の生活文化 中 | 横井清 著, 講談社, 2007.12, 中, 192p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 18 | 器量人の研究 | 童門冬二 著, PHP研究所, 2007.9, 256p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 19 | 京都高瀬川 : 角倉了以・素庵の遺産 | 石田孝喜 著, 思文閣, 2005.8, 267, 19p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 20 | 金は天下のまわりもの : 金儲けできる人できない人 | 泉秀樹 著, グラフ社, 2005.1, 187p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 21 | 江戸人物科学史 : 「もう一つの文明開化」を訪ねて | 金子務 著, 中央公論新社, 2005.12, 340p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 22 | 保津の夜明け | ゆらただし 著, 新風舎, 2003.11, 141p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 23 | おらんだ正月 : 新編 | 森銑三 著 ; 小出昌洋 編, 岩波書店, 2003.1, 404p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 24 | 大事業をおこした技術者列伝 : ブルーネル/ソルベー/ツィオルコフスキー | 竹内 均【編】, ニュートンプレス, 2003.6, 238p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 25 | 歴史に学ぶ後継者育成の経営術 | 童門冬二 著, 廣済堂, 2002.3, 290p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 26 | 江戸時代の61人 | PHP研究所 編, PHP研究所, 2001.2, 47p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 27 | 風浪の海 | 澤田ふじ子 著, 廣済堂, 2001.11, 309p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 28 | 新世紀 : 16人の先達 : 新世紀の日本型理念経営のすすめ | 日本経営倫理学会・理念哲学研究部会 編著, 英治, 2001.2, 262p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 29 | Newton 20(9) | 教育社 [編], 教育社, 2000-09, 20(9), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 30 | 江戸の生活と経済 | 宮林義信 著, 三一書房, 1998.8, 221p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| ... | ... | ... | ... |
| 142 | 日本歴史図録 : 2巻 下巻 | 高橋健自 等編, 歴史参考図刊行会, 1918, 下巻, 2冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 143 | とはずがたり | 松本幹一 著, 泰山房, 大正6, 358p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 144 | 文武仁侠大和錦 | 中山蕗峰 著, 東洋興立教育会出版部, 大正6, 642p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 145 | 内外教訓物語 人之巻 | 馬淵冷佑 編, 宝文館, 明42-大4, 人之巻, 3冊 (天565, 地574, 人619... | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 146 | 近世奇人伝 : 選評 | 蒿蹊大人 著, 大川屋書店, 大正1, 162p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 147 | 愛国百話 | 足立栗園 著, 積善館, 明44.12, 320p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 148 | 少年武士道 | 谷口政徳 編, 聚栄堂大川書店, 明44.3, 287p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 149 | 英雄物語 : 良民講和 | 河本亀之助 編, 良民社, 明44.9, 110p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 150 | 史学叢説 第2集 | 星野恒 稿 ; 星野幹, 星野彬 共編, 富山房, 明治42, 第2集, 2冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 151 | 史学叢説 第2集 | 星野恒 稿 ; 星野幹, 星野彬 編, 富山房, 1909, 第2集, 776p 図版 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 152 | 近世畸人伝 続 | 伴蒿蹊 著 ; 三熊花顛 画, 青木嵩山堂, 明42.6, 続, 2冊 (375, 続366... | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 153 | 好古類纂 三編 第三集 | 好古社 編, 好古社, 明治33-42, 三編 第三集, 38冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 154 | 先哲墨宝 甲 | 報徳講演会 編, 山田芸艸堂, 明41.12, 甲, 2冊 (解説共) | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 155 | 歴史地理 10(3) | 日本歴史地理研究會, 日本歴史地理研究會, 1907-09, 10(3), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 156 | 国定教科書を使用する国語綴り方教授精案 尋常科第4学年 後期 | 普通教育研究会 編 ; 鈴木静 閲, 鍾美堂, 明37, 尋常科第4学年 後期, 7冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 157 | 近世立志伝 第5 河村瑞軒 | 足立栗園 著, 積善館, 明35-36, 第5 河村瑞軒, 7冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 158 | 先哲遺芳 | 京都府教育会 編, 芸艸堂, 明36.8, 27p 図版30枚 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 159 | 智と徳 | 谷口流鶯 著, 松声堂, 明34.2, 95p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 160 | 少年叢書 | 谷口流鶯 著, 上田屋, 明32.2, 1冊 (合本) | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 161 | 新撰日本小歴史 | 高橋精軒 編, 盛林堂, 明32.2, 127p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 162 | 富豪立身談 : 実業教育 | 谷口政徳 編, 上田屋, 明32.1, 141p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 163 | 頴才新誌 (1039) | --, 頴才新誌社, 1897-09, (1039), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 164 | 頴才新誌 (1040) | --, 頴才新誌社, 1897-09, (1040), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 165 | 歴史修身談 : 新体教育 | 高橋光正 編, 林甲子太郎, 明30.3, 118p, | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 166 | 新編国文読本 巻の1 下 | 国語研究会 編, 富山房, 明28-29, 訂正, 巻の1 下, 10冊 (5巻) | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 167 | 中学国文読本 第4 | 新保磐次 編, 金港堂, 明28.8, 訂正再版, 第4, 10冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 168 | 小国民 4(22) | --, 不二, 1892-11, 復刻版, 4(22), 17冊 (別冊とも) | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 169 | 少國民 第4年(22) | 鳴皐書院 [編], 鳴皐書院, 1892-11, 第4年(22), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 170 | 新撰高等日本讀本 上編 第3 | 金港堂書籍株式會社編輯所 編輯, 金港堂書籍, 1891.12, 訂正再版, 上編 第3, ... | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 171 | 土木ニュース 19(2) | --, シビル社, 0000, 19(2), 冊 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
171 rows × 3 columns
%selectstr¶
先ほどの検索結果は、さすがに多すぎるので、絞り込む。
%selectstrは、与えたデータフレームから、コラム名で指定した列(コラム/フィールド)に検索文字列が含まれるものを抜き出すコマンド。
ここでは、直近の出力結果(データフレーム)から、titleフィールドに「角倉」が含まれているものを抜き出しておき、変数wbibに代入しておく。
wbib = %selectstr _, title, 角倉
wbib
| title | description | url | |
|---|---|---|---|
| 2 | 角倉一族とその時代 | 森洋久 編, 思文閣, 2015.7, 617,5p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 5 | 角倉了以の世界 | 宮田章 著, 大成出版社, 2013.4, 163p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 10 | 角倉了以と富士川 | 淡路一朗 著, 山梨ふるさと文庫, 2011.4, 373p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 12 | この者、只者にあらず : 角倉了以 | 中田有紀子 著, 致知出版社, 2009.12, 303p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 19 | 京都高瀬川 : 角倉了以・素庵の遺産 | 石田孝喜 著, 思文閣, 2005.8, 267, 19p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 85 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 野村尚吾 著, 毎日新聞社, 1968, 222p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 112 | 角倉了以とその子 | 林屋辰三郎 著, 星野書店, 昭和19, 201p 図版 肖像 | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 113 | 角倉了以とその子 | 林屋辰三郎 著, 星野書店, 1944, 201p 図版12p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
| 116 | 南方先覚者角倉了以と玄之 | 階本樹著, 角倉了以父子顕彰會, 1943, 47, 4p | http://webcatplus.nii.ac.jp//webcatplus/detail... |
%amazonmap, %amazonPmap¶
もう一つ、文献リストづくりの道具を紹介しておく。 %amazonmapと%amazonPmapは、アマゾンの関連商品を辿って関連マップをつくるコマンド。巡った商品をデータフレーム(表)にして書き出すこともできる。
%amazonmapと%amazonPmapの違いは、%amazonmapはタイトル(題名)を結ぶマップを作るが、%amazonPmapは商品画像(書籍な表紙の画像)を結ぶマップをつくる。書籍の題名は長いことが多いので、画像によるマップのほうが図がコンパクトにまとまる感じがする。
%amazonmap t
depth: 1 width: 5 . . . . . . . . . . . . . . . . . . . . . . . . . . .
<__main__.AmazonRelateMap at 0x10af8c1d0>
これでAmazonRelateMapオブジェクトができたので、グラフ化のメソッド.g()を使って表紙を結ぶマップを描く。
_ アンダバーで直前の出力を参照してる。
_.g()
同じく、AmazonRelateMapオブジェクトに、データフレーム化のメソッド.df()を使って文献リストを作る。
__ アンダバー2つで、2つ前の出力を参照してる。
__.df()
| url | title | asin | shape | |
|---|---|---|---|---|
| 1 | http://www.amazon.co.jp/dp/4779010004 | 曳舟の道: 京の豪商、角倉了以・素庵物語 | 4779010004 | plaintext |
| 2 | http://www.amazon.co.jp/dp/4802830815 | 角倉了以の世界 | 4802830815 | plaintext |
| 3 | http://www.amazon.co.jp/dp/4903680320 | 角倉了以と富士川 | 4903680320 | plaintext |
| 4 | http://www.amazon.co.jp/dp/4122017378 | 嵯峨野明月記 (中公文庫) | 4122017378 | plaintext |
| 5 | http://www.amazon.co.jp/dp/4122054044 | 後水尾天皇 (中公文庫) | 4122054044 | plaintext |
| 6 | http://www.amazon.co.jp/dp/4784217975 | 角倉一族とその時代 | 4784217975 | plaintext |
| 7 | http://www.amazon.co.jp/dp/4106037661 | 豊臣大坂城: 秀吉の築城・秀頼の平和・家康の攻略 (新潮選書) | 4106037661 | plaintext |
| 8 | http://www.amazon.co.jp/dp/4404038720 | 徳川家康のスペイン外交 | 4404038720 | plaintext |
| 9 | http://www.amazon.co.jp/dp/4642058044 | 天下統一とシルバーラッシュ: 銀と戦国の流通革命 (歴史文化ライブラリー) | 4642058044 | plaintext |
| 10 | http://www.amazon.co.jp/dp/4004315220 | 戦国乱世から太平の世へ〈シリーズ 日本近世史 1〉 (岩波新書) | 4004315220 | plaintext |
| 11 | http://www.amazon.co.jp/dp/4062807157 | 東インド会社とアジアの海 (興亡の世界史) | 4062807157 | plaintext |
これも%selectstrでtitleに「角倉」を含むものだけを抜いて、変数abibに代入しておく。
abib = %selectstr _, title, 角倉
abib
| url | title | asin | shape | |
|---|---|---|---|---|
| 1 | http://www.amazon.co.jp/dp/4779010004 | 曳舟の道: 京の豪商、角倉了以・素庵物語 | 4779010004 | plaintext |
| 2 | http://www.amazon.co.jp/dp/4802830815 | 角倉了以の世界 | 4802830815 | plaintext |
| 3 | http://www.amazon.co.jp/dp/4903680320 | 角倉了以と富士川 | 4903680320 | plaintext |
| 6 | http://www.amazon.co.jp/dp/4784217975 | 角倉一族とその時代 | 4784217975 | plaintext |
%makebib¶
%makebibは、複数の文献データフレームを統合して、抜けてる情報を補完して文献リストを仕上げるためのコマンド。
%webcat由来のwbibと%amazonPmap由来のabibを合わせて、各種コードやサマリーや出版者名、発行年、頁数、目次情報などを補完している。
mybib = %makebib abib, wbib
mybib
. . . . . . . . . . . . .
| isbn | ncid | nbn | title | author | publisher | issued | pages | summary | contents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 978-4-7790-1000-2 | 22293360 | 曳舟の道 | 濱岡三太郎 著 | 幻冬舎ルネッサンス | 2013.8 | 245p | 秀吉の朝鮮出兵が始まった頃のこと。京の一商人・角倉了以は朱印船貿易を終えた帰途、備前・吉井川... | ||
| 2 | 978-4-8028-3081-2 | BB1228364X | 22230547 | 角倉了以の世界 | 宮田章 著 | 大成出版社 | 2013.4 | 163p | 第1章 了以の理想\t第2章 朱印船貿易\t第3章 筏流し\t第4章 権力との繋がり\t第5... | |
| 3 | 978-4-903680-32-3 | BB09350104 | 21941368 | 角倉了以と富士川 | 淡路一朗 著 | 山梨ふるさと文庫 | 2011.4 | 373p | ||
| 4 | 978-4-7842-1797-7 | BB19067700 | 22632385 | 角倉一族とその時代 | 森洋久 編 | 思文閣 | 2015.7 | 617,5p | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜\t第2部 吉田家の医業\t第3部 社会基盤と角倉\t第4部 海外... |
| 5 | 978-4-7842-1797-7 | BB19067700 | 22632385 | 角倉一族とその時代 | 森洋久 編 | 思文閣 | 2015.7 | 617,5p | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜\t第2部 吉田家の医業\t第3部 社会基盤と角倉\t第4部 海外... |
| 6 | 978-4-8028-3081-2 | BB1228364X | 22230547 | 角倉了以の世界 | 宮田章 著 | 大成出版社 | 2013.4 | 163p | 第1章 了以の理想\t第2章 朱印船貿易\t第3章 筏流し\t第4章 権力との繋がり\t第5... | |
| 7 | 978-4-903680-32-3 | BB09350104 | 21941368 | 角倉了以と富士川 | 淡路一朗 著 | 山梨ふるさと文庫 | 2011.4 | 373p | ||
| 8 | 978-4-88474-870-8 | BB0252903X | 21699968 | この者、只者にあらず : 角倉了以 | 中田有紀子 著 | 致知出版社 | 2009.12 | 303p | 志を立て、私財を投じ、京都・保津川を開き、高瀬川をつくった男。日本の企業家精神は、ここからは... | |
| 9 | 4784212531 | BA73380187 | 20860243 | 京都高瀬川 : 角倉了以・素庵の遺産 | 石田孝喜 著 | 思文閣 | 2005.8 | 267, 19p | 第1章 高瀬舟は行く\t第2章 鴨川と高瀬川\t第3章 高瀬川の開削\t第4章 高瀬川を歩く... | |
| 10 | BN0743155X | 68013076 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 野村尚吾 著 | 毎日新聞社 | 1968 | 222p | 目次 \tはじめに \t嵯峨という土地 \tその特殊性の由来 / p13\t交互に現われる血... | ||
| 11 | 46006593 | 角倉了以とその子 | 林屋辰三郎 著 | 星野書店 | 昭和19 | 201p 図版 肖像 | ||||
| 12 | BN09189885 | 58007959 | 角倉了以とその子 | 林屋辰三郎 著 | 星野書店 | 1944 | 201p 図版12p | 標題 \t目次 \t序 / 1\t第一章 父祖と家業 / 11\t第二章 安南國貿易 / 4... | ||
| 13 | BN11972994 | 南方先覚者角倉了以と玄之 | 階本樹著 | 角倉了以父子顕彰會 | 1943 | 47, 4p |
%selectindexを使って、目次情報を持っているものだけを抜き出している。
%selectindex mybib, 2,4:6,9:10,12
| isbn | ncid | nbn | title | author | publisher | issued | pages | summary | contents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 978-4-8028-3081-2 | BB1228364X | 22230547 | 角倉了以の世界 | 宮田章 著 | 大成出版社 | 2013.4 | 163p | 第1章 了以の理想\t第2章 朱印船貿易\t第3章 筏流し\t第4章 権力との繋がり\t第5... | |
| 4 | 978-4-7842-1797-7 | BB19067700 | 22632385 | 角倉一族とその時代 | 森洋久 編 | 思文閣 | 2015.7 | 617,5p | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜\t第2部 吉田家の医業\t第3部 社会基盤と角倉\t第4部 海外... |
| 5 | 978-4-7842-1797-7 | BB19067700 | 22632385 | 角倉一族とその時代 | 森洋久 編 | 思文閣 | 2015.7 | 617,5p | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜\t第2部 吉田家の医業\t第3部 社会基盤と角倉\t第4部 海外... |
| 6 | 978-4-8028-3081-2 | BB1228364X | 22230547 | 角倉了以の世界 | 宮田章 著 | 大成出版社 | 2013.4 | 163p | 第1章 了以の理想\t第2章 朱印船貿易\t第3章 筏流し\t第4章 権力との繋がり\t第5... | |
| 9 | 4784212531 | BA73380187 | 20860243 | 京都高瀬川 : 角倉了以・素庵の遺産 | 石田孝喜 著 | 思文閣 | 2005.8 | 267, 19p | 第1章 高瀬舟は行く\t第2章 鴨川と高瀬川\t第3章 高瀬川の開削\t第4章 高瀬川を歩く... | |
| 10 | BN0743155X | 68013076 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 野村尚吾 著 | 毎日新聞社 | 1968 | 222p | 目次 \tはじめに \t嵯峨という土地 \tその特殊性の由来 / p13\t交互に現われる血... | ||
| 12 | BN09189885 | 58007959 | 角倉了以とその子 | 林屋辰三郎 著 | 星野書店 | 1944 | 201p 図版12p | 標題 \t目次 \t序 / 1\t第一章 父祖と家業 / 11\t第二章 安南國貿易 / 4... |
目次情報を持っているものを抜き出したので、contents列にまとめられた目次を、%expand_contentコマンドを使って、バラして展開している。
つまり%expand_contentは、目次マトリクスをつくるのを助けるコマンドである。
目次マトリクスについては下記の記事を参照のこと。
- 複数の文献を一望化し横断的読みを実装するコンテンツ・マトリクスという方法 読書猿Classic: between / beyond readers変更する
%expand_content _
| title | summary | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ... | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 角倉了以の世界 | 第1章 了以の理想 | 第2章 朱印船貿易 | 第3章 筏流し | 第4章 権力との繋がり | 第5章 保津川通船工事 | 第6章 富士川 | 第7章 京高瀬川 | 第8章 了以没後 | ... | |||||||||||
| 4 | 角倉一族とその時代 | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜 | 第2部 吉田家の医業 | 第3部 社会基盤と角倉 | 第4部 海外貿易と船の技術 | 第5部 算術 | 第6部 瑳峨本と古活字 | 〈嵯峨本〉以前の古活字版について - 森上修 | 『塵劫記』から和算へ - 小寺裕 | ... | ||||||||||
| 5 | 角倉一族とその時代 | 了以・素庵による朱印船貿易、高瀬川・保津川・富士川の開削-、近世角倉一族は大商人・事業家とし... | 第1部 吉田・角倉家の系譜 | 第2部 吉田家の医業 | 第3部 社会基盤と角倉 | 第4部 海外貿易と船の技術 | 第5部 算術 | 第6部 瑳峨本と古活字 | 〈嵯峨本〉以前の古活字版について - 森上修 | 『塵劫記』から和算へ - 小寺裕 | ... | ||||||||||
| 6 | 角倉了以の世界 | 第1章 了以の理想 | 第2章 朱印船貿易 | 第3章 筏流し | 第4章 権力との繋がり | 第5章 保津川通船工事 | 第6章 富士川 | 第7章 京高瀬川 | 第8章 了以没後 | ... | |||||||||||
| 9 | 京都高瀬川 : 角倉了以・素庵の遺産 | 第1章 高瀬舟は行く | 第2章 鴨川と高瀬川 | 第3章 高瀬川の開削 | 第4章 高瀬川を歩く | 第5章 高瀬舟 | 第6章 高瀬舟運の推移 | ... | |||||||||||||
| 10 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 目次 | はじめに | 嵯峨という土地 | その特殊性の由来 / p13 | 交互に現われる血脈 / p18 | 〝帯座〟による別途収入 / p27 | 若き了以の環境 | 早婚による独立 / p33 | ... | 博多と朝鮮の役 / p184 | 長崎の末次平蔵 / p191 | 東・西末吉家の明暗 / p196 | 豪商の発生条件 | 拾頭の地盤 / p201 | 共通する性格 / p206 | 町衆との関係 / p209 | 鎖国と次代の豪商たち / p215 | あとがき | ||
| 12 | 角倉了以とその子 | 標題 | 目次 | 序 / 1 | 第一章 父祖と家業 / 11 | 第二章 安南國貿易 / 49 | 第三章 諸川の疏鑿 / 89 | 第四章 學問の愛好 / 127 | 第五章 素庵と光悅 / 155 | ... |
7 rows × 55 columns
%amazonreviews¶
%amazonreviewsに文献データフレームを渡すと、アマゾンのレビューを拾ってきてくれる。
%amazonreviews mybib
. . . . . . . . . . . . .
| isbn | book_title | review_title | description | des_size | |
|---|---|---|---|---|---|
| 1 | 978-4-8028-3081-2 | 角倉了以の世界 | 図書館や学校に是非備えてほしい一冊。 | よく知られているとは言えない江戸初期の豪商「角倉了以」の事業者としての生き様と足跡を、建設業... | 444 |
| 2 | 978-4-8028-3081-2 | 角倉了以の世界 | なぜかマイナーな角倉了以 | 朱印船貿易を行うほどの大商人であり、私財でいくつも河川開拓をやって当時の流通まで変えてしまう... | 303 |
| 3 | 978-4-903680-32-3 | 角倉了以と富士川 | よく調べられた労作 | これまで角倉了以に関する図書を数冊読んだが、本書は非常によく調査された労作だと思います。著者... | 94 |
| 4 | 978-4-8028-3081-2 | 角倉了以の世界 | 図書館や学校に是非備えてほしい一冊。 | よく知られているとは言えない江戸初期の豪商「角倉了以」の事業者としての生き様と足跡を、建設業... | 444 |
| 5 | 978-4-8028-3081-2 | 角倉了以の世界 | なぜかマイナーな角倉了以 | 朱印船貿易を行うほどの大商人であり、私財でいくつも河川開拓をやって当時の流通まで変えてしまう... | 303 |
| 6 | 978-4-903680-32-3 | 角倉了以と富士川 | よく調べられた労作 | これまで角倉了以に関する図書を数冊読んだが、本書は非常によく調査された労作だと思います。著者... | 94 |
| 7 | 978-4-88474-870-8 | この者、只者にあらず | 研究書なのか?時代小説なのか? | 角倉了似という教科書でしか見たことが無い歴史上の人物にスポットを当てて書籍にされたということ... | 649 |
| 8 | 978-4-88474-870-8 | この者、只者にあらず | 良い本でした | 角倉了以の生涯だけでなく時代背景や一族のことももきちんと書いてあり、大変参考になりました。欲... | 83 |
所在調査¶
ライブラリ・リサーチは、知りたいトピック/解きたい問いからはじまり、それを文献リストの形に変え、実際に文献を手に入れるところで折り返す。
すべての文献が手に入ることは難しいが、最寄りの図書館、ネット書店、最終手段の順に所在/在庫を確かめる作業へ進もう。
最寄りの図書館 %librarylist¶
最寄りの図書館は、ライブラリ・リサーチの第一拠点である。繰り返し使うことになるから登録しておこう。
%librarylist (地名/駅名など)で、まず図書館リストをつくる。
%librarylist 国立市
東京都 国立市 内の図書館を検索
| systemid | systemname | formal | address | tel | geocode | category | url_pc | |
|---|---|---|---|---|---|---|---|---|
| 1 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館下谷保分室 | 東京都国立市谷保5066 下谷保地域防災センター内 | 042-580-7215 | 139.4488938,35.6797741 | SMALL | https://www.library-kunitachi.jp/kakukan.html#2 |
| 2 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館 | 東京都国立市富士見台2-34 | 042-576-0161 | 139.444389,35.685145 | MEDIUM | https://www.library-kunitachi.jp/kakukan.html#2 |
| 3 | Tokyo_Kunitachi | 東京都国立市 | 国立市公民館図書室 | 東京都国立市中1-15-3 | 042-572-5141 | 139.443458,35.696882 | SMALL | http://www.city.kunitachi.tokyo.jp/kominkan/00... |
| 4 | Tokyo_Kunitachi | 東京都国立市 | くにたち北市民プラザ図書館 | 東京都国立市北3-1-1 北三丁目アパート9号棟1階 | 042-580-7220 | 139.4303382,35.7017063 | MEDIUM | https://www.library-kunitachi.jp/kakukan.html#2 |
| 5 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館南市民プラザ分室 | 東京都国立市泉2-3-2 泉二丁目アパート1号棟1階 | 042-580-7216 | 139.4314699,35.6737222 | SMALL | https://www.library-kunitachi.jp/kakukan.html#2 |
| 6 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館東分室 | 東京都国立市東3-18-32 東福祉館内 | 042-580-7219 | 139.4547983,35.6914284 | SMALL | https://www.library-kunitachi.jp/kakukan.html#2 |
| 7 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館谷保東分室 | 東京都国立市谷保135-1 谷保東集会所内 | 042-580-7214 | 139.4506913,35.6730944 | SMALL | https://www.library-kunitachi.jp/kakukan.html#2 |
| 8 | Tokyo_Kunitachi | 東京都国立市 | くにたち中央図書館青柳分室 | 東京都国立市青柳244 青柳福祉センター内 | 042-540-7367 | 139.4246508,35.6862119 | SMALL | https://www.library-kunitachi.jp/kakukan.html#2 |
| 9 | Univ_Hitotsubashi | 一橋大学 | 一橋大学附属図書館 | 東京都国立市中2丁目1 | 042-580-8224 | 139.443999,35.694316 | UNIV | http://www.lib.hit-u.ac.jp/ |
| 10 | Univ_Hitotsubashi | 一橋大学 | 一橋大学経済研究所附属社会科学統計情報研究センター | 東京都国立市中2-1 | 042-580-8391 | 139.4426047,35.6942724 | UNIV | http://rcisss.ier.hit-u.ac.jp/Japanese/ |
| 11 | Univ_Hitotsubashi | 一橋大学 | 一橋大学経済研究所資料室 | 東京都国立市中2-1 | 042-580-8320 | 139.443549,35.695074 | UNIV | http://www.ier.hit-u.ac.jp/library/Japanese/ |
| 12 | Univ_Twcpe | 東京女子体育大学 | 東京女子体育大学・東京女子体育短期大学図書館 | 東京都国立市富士見台4-30-1 | 042-572-4131 | 139.428365,35.689365 | UNIV | http://www.twcpe.ac.jp/library/ |
とりあえず2つめのくにたち中央図書館を%selectindexで抽出して、変数mytownlibraryに代入しておく
mytownlibrary = %selectindex _,2
%librarystatus¶
%librarystatusに、文献データフレームと図書館リストフレームを与えると、それぞれの文献が、与えられた図書館群に所蔵されているか、貸出可能かどうかの一覧を作ってくれる。
%librarystatus mybib, mytownlibrary
| isbn | title | library | status | url | |
|---|---|---|---|---|---|
| 1 | 978-4-88474-870-8 | この者、只者にあらず : 角倉了以 | くにたち中央図書館 | 貸出可 | http://www.library-kunitachi.jp/opw/OPW/OPWSRC... |
1冊しか見つからなかった。これではあんまりなので、手を広げて所蔵調査を続けよう。
%stocks_amazon¶
文献リストの入っているmybibを%stocks_amazonに与えて、アマゾンの在庫と値段を確認する。
%stocks_amazon mybib
. . . . . . . . . . . . .
| asin | listprice | lowestnewprice | lowestusedprice | title | totalnew | totalused | url | |
|---|---|---|---|---|---|---|---|---|
| 1 | 4884748700 | ¥ 1,836 | ¥ 1,836 | ¥ 204 | この者、只者にあらず | 1 | 9 | http://www.amazon.co.jp/dp/4884748700/ |
| 2 | 4784212531 | ¥ 2,376 | None | ¥ 3,500 | 京都 高瀬川―角倉了以・素庵の遺産 | 0 | 11 | http://www.amazon.co.jp/dp/4784212531/ |
| 3 | 4779010004 | ¥ 1,512 | ¥ 1,512 | None | 曳舟の道: 京の豪商、角倉了以・素庵物語 | 1 | 0 | http://www.amazon.co.jp/dp/4779010004/ |
| 4 | 4784217975 | ¥ 9,504 | ¥ 9,504 | ¥ 7,508 | 角倉一族とその時代 | 1 | 4 | http://www.amazon.co.jp/dp/4784217975/ |
| 5 | 4784217975 | ¥ 9,504 | ¥ 9,504 | ¥ 7,508 | 角倉一族とその時代 | 1 | 4 | http://www.amazon.co.jp/dp/4784217975/ |
| 6 | B000JAUYES | NaN | None | None | 角倉了以とその子 (1944年) | 0 | 0 | http://www.amazon.co.jp/dp/B000JAUYES/ |
| 7 | B000JAUYES | NaN | None | None | 角倉了以とその子 (1944年) | 0 | 0 | http://www.amazon.co.jp/dp/B000JAUYES/ |
| 8 | 4903680320 | ¥ 2,160 | ¥ 2,160 | ¥ 1,680 | 角倉了以と富士川 | 2 | 5 | http://www.amazon.co.jp/dp/4903680320/ |
| 9 | 4903680320 | ¥ 2,160 | ¥ 2,160 | ¥ 1,680 | 角倉了以と富士川 | 2 | 5 | http://www.amazon.co.jp/dp/4903680320/ |
| 10 | 4802830815 | ¥ 2,700 | ¥ 2,700 | ¥ 2,300 | 角倉了以の世界 | 1 | 3 | http://www.amazon.co.jp/dp/4802830815/ |
| 11 | 4802830815 | ¥ 2,700 | ¥ 2,700 | ¥ 2,300 | 角倉了以の世界 | 1 | 3 | http://www.amazon.co.jp/dp/4802830815/ |
| 12 | B000JA3U3U | ¥ 389 | None | ¥ 600 | 豪商―角倉了以を中心とする戦国大商人の誕生 (1968年) | 0 | 5 | http://www.amazon.co.jp/dp/B000JA3U3U/ |
随分と見つかったが、日本大百科全書にも朝日日本歴史人物事典にも挙がっていた『角倉了以とその子』が品切れで入手できないのは痛恨である。
さらに手を広げて所蔵調査を続けよう。
%stocks_kosho¶
文献リストの入っているmybibを%stocks_koshoに与えて、「日本の古本屋」の在庫と出品店と値段を確認する。
%stocks_kosho mybib
. . . . . . . . . . . . .
| title | info | price | url | |
|---|---|---|---|---|
| 1 | この者、只者にあらず 角倉了以 | 啓仙堂 富山県高岡市福岡町土屋 ... | 800 | https://www.kosho.or.jp/products/detail.php?pr... |
| 2 | 京都高瀬川 : 角倉了以・素庵の遺産 | 海月文庫 大阪府大阪市淀川区木川東 ... | 3,500 | https://www.kosho.or.jp/products/detail.php?pr... |
| 3 | 角倉一族とその時代 | とらや書店 茨城県水戸市三の丸 ... | 7,560 | https://www.kosho.or.jp/products/detail.php?pr... |
| 4 | 角倉一族とその時代 | 高原書店 東京都町田市森野 ... | 6,588 | https://www.kosho.or.jp/products/detail.php?pr... |
| 5 | 角倉一族とその時代 | とらや書店 茨城県水戸市三の丸 ... | 7,560 | https://www.kosho.or.jp/products/detail.php?pr... |
| 6 | 角倉一族とその時代 | 高原書店 東京都町田市森野 ... | 6,588 | https://www.kosho.or.jp/products/detail.php?pr... |
| 7 | 角倉了以とその子 | 沙羅書房 東京都千代田区神田神保町 ... | 19,440 | https://www.kosho.or.jp/products/detail.php?pr... |
| 8 | 角倉了以とその子 | 叢文閣書店 東京都千代田区神田神保町 ... | 10,000 | https://www.kosho.or.jp/products/detail.php?pr... |
| 9 | 角倉了以とその子 | 沙羅書房 東京都千代田区神田神保町 ... | 19,440 | https://www.kosho.or.jp/products/detail.php?pr... |
| 10 | 角倉了以とその子 | 叢文閣書店 東京都千代田区神田神保町 ... | 10,000 | https://www.kosho.or.jp/products/detail.php?pr... |
| 11 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 光国家書店 大阪府豊中市庄内栄町 ... | 900 | https://www.kosho.or.jp/products/detail.php?pr... |
ようやく『角倉了以とその子』が見つかった。しかし、予想通り、結構な価格である。 最終手段に進む必要がありそうだ。
%stocks_ndl¶
文献リストの入っているmybibを%stocks_ndl に与えると、国会図書館及び、地域の中心的機能を担う各県立図書館の蔵書が確認できる。
%stocks_ndl mybib
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
| title | library_name | availability | description | url | |
|---|---|---|---|---|---|
| 1 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 国立国会図書館 | http://id.ndl.go.jp/bib/024759397 | ||
| 2 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | さいたま市立中央図書館 | 配置場所 : 一般 | ||
| 3 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 京都府立図書館 | 利用可 | 配置場所 : 1F開架 | |
| 4 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 大阪市立図書館 | http://web.oml.city.osaka.lg.jp/webopac_i_ja/0... | ||
| 5 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 岡山県立図書館 | 貸出可 | 配置場所 : 配本コーナ | |
| 6 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 大阪府立中央図書館 | https://www.library.pref.osaka.jp/licsxp-opac/... | ||
| 7 | 曳舟の道 : 京の豪商、角倉了以・素庵物語 | 長崎県立長崎図書館 | 帯出可 | 配置場所 : 開架図書 | |
| 8 | 角倉了以の世界 | 国立国会図書館 | http://id.ndl.go.jp/bib/024353764 | ||
| 9 | 角倉了以の世界 | 広島市立中央図書館 | 可能 | 配置場所 : 閲B | |
| 10 | 角倉了以の世界 | 山梨県立図書館 | 貸可複可閲可 | 配置場所 : 2階一般 | |
| 11 | 角倉了以の世界 | 京都府立図書館 | 利用可 | 配置場所 : B1開架 | |
| 12 | 角倉了以の世界 | 神奈川県立図書館 | 配置場所 : 県立 | ||
| 13 | 角倉了以の世界 | 富山県立図書館 | 帯出可 | 配置場所 : 一般開架 | |
| 14 | 角倉了以の世界 | 川崎市立中原図書館 | |||
| 15 | 角倉了以の世界 | 福岡県立図書館 | 貸出可能資料 | 所蔵場所 : 一般閲覧室 | http://www.lib.pref.fukuoka.jp/winj/opac/switc... |
| 16 | 角倉了以の世界 | 岡山県立図書館 | 貸出可 | 配置場所 : 1F人文 | |
| 17 | 角倉了以の世界 | 千葉県立東部図書館 | 利用可能 | 配置場所 : 一般開架 | |
| 18 | 角倉了以の世界 | 大阪府立中央図書館 | https://www.library.pref.osaka.jp/licsxp-opac/... | ||
| 19 | 角倉了以の世界 | 県立長野図書館 | https://www.library.pref.nagano.jp/licsxp-opac... | ||
| 20 | 角倉了以の世界 | 京都府立総合資料館 | 参考図書 | http://opacs.pref.kyoto.lg.jp/mylimedio/search... | |
| 21 | 角倉了以の世界 | 東京都立中央図書館 | 閲可/個否/協可 | 配置場所 : 3FC開 | |
| 22 | 角倉了以と富士川 | 国立国会図書館 | http://id.ndl.go.jp/bib/000011185648 | ||
| 23 | 角倉了以と富士川 | 山梨県立図書館 | 貸可複可閲可 | 配置場所 : 特コレ | |
| 24 | 角倉了以と富士川 | 京都府立図書館 | 利用可 | 配置場所 : 自動書庫 | |
| 25 | 角倉一族とその時代 | 国立国会図書館 | http://id.ndl.go.jp/bib/026580732 | ||
| 26 | 角倉一族とその時代 | 大阪府立中央図書館 | https://www.library.pref.osaka.jp/licsxp-opac/... | ||
| 27 | 角倉一族とその時代 | 鹿児島県立図書館 | 貸出可 | 配置場所 : 2階閲覧室 | |
| 28 | 角倉一族とその時代 | 大分県立図書館 | 帯出可 | 配置場所 : 一般資料室 | |
| 29 | 角倉一族とその時代 | 京都府立図書館 | 利用可 | 配置場所 : 1F開架 | |
| 30 | 角倉一族とその時代 | 神奈川県立図書館 | 配置場所 : 県立 | ||
| ... | ... | ... | ... | ... | ... |
| 124 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 福島県立図書館 | 帯出可 | 配置場所 : 書庫小文字 | |
| 125 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 秋田県立図書館 | 帯出可 | 配置場所 : 4階昭和戦後収集図書 | |
| 126 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 静岡県立中央図書館 | 0 | 配置場所 : 静岡県立中央図書館 | |
| 127 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 石川県立図書館 | 貸出可 | 配置場所 : 書庫 | |
| 128 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 富山県立図書館 | 帯出可 | 配置場所 : 書庫 | |
| 129 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 福岡市総合図書館 | 禁帯出 | ||
| 130 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 札幌市中央図書館 | 帯出可 | ||
| 131 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 名古屋市鶴舞中央図書館 | 貸出可 | ||
| 132 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 滋賀県立図書館 | 貸出可 | 配置場所 : 一般書庫B2階 | |
| 133 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 鳥取県立図書館 | 可能 | 配置場所 : 一般H | |
| 134 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 広島県立図書館 | 可能 | 配置場所 : 3A | |
| 135 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 岩手県立図書館 | 持出可能 | 配置場所 : 集密書庫 | |
| 136 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 鹿児島県立図書館 | |||
| 137 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 新潟県立図書館 | 配置場所 : 書庫2門 | ||
| 138 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 奈良県立図書情報館 | 配置場所:一般書庫 | http://opacsvr01.library.pref.nara.jp/mylimedi... | |
| 139 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 愛知県図書館 | 閲可貸可協可 | 所蔵場所 : 書庫B2 | http://websv.aichi-pref-library.jp/winj/opac/s... |
| 140 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 大阪市立図書館 | http://web.oml.city.osaka.lg.jp/webopac_i_ja/0... | ||
| 141 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 福岡県立図書館 | 貸出可能資料 | 所蔵場所 : 書庫 | http://www.lib.pref.fukuoka.jp/winj/opac/switc... |
| 142 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 千葉県立中央図書館 | 利用可能 | 配置場所 : 一般書庫 | |
| 143 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 千葉県立西部図書館 | 利用可能 | 配置場所 : 中央預り図書(書庫CL) | |
| 144 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 大阪府立中央図書館 | https://www.library.pref.osaka.jp/licsxp-opac/... | ||
| 145 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 大阪府立中之島図書館 | https://www.library.pref.osaka.jp/licsxp-opac/... | ||
| 146 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 宮城県図書館 | 貸出・閲覧可 | 配置場所 : 一4:一般書庫4 | http://www.library.pref.miyagi.jp/wo/opc_srh/s... |
| 147 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 三重県立図書館 | 持出可能 | 所蔵場所 : 閉架(一般) | http://opac1.library.pref.mie.lg.jp/winj/opac/... |
| 148 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 茨城県立図書館 | https://www.lib.pref.ibaraki.jp//licsxp-opac/W... | ||
| 149 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 京都府立総合資料館 | 参考図書 | http://opacs.pref.kyoto.lg.jp/mylimedio/search... | |
| 150 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 東京都立中央図書館 | 閲可/個否/協止 | 配置場所 : B2書庫A | |
| 151 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 横浜市中央図書館 | 配置場所 : 書庫(人文科学中央) | ||
| 152 | 豪商 : 角倉了以を中心とする戦国大商人の誕生 | 島根県立図書館 | 利用可 | 所蔵場所 : 地下書庫 | https://www2.library.pref.shimane.lg.jp/opac/s... |
| 153 | 角倉了以とその子 | 国立国会図書館 | http://id.ndl.go.jp/bib/000000668159 |
153 rows × 5 columns
%selectstr _,title,角倉了以とその子
| title | library_name | availability | description | url | |
|---|---|---|---|---|---|
| 153 | 角倉了以とその子 | 国立国会図書館 | http://id.ndl.go.jp/bib/000000668159 |
目的の書物は、例の場所に所蔵されていた。
なおURL の http://id.ndl.go.jp/bib/000000668159 からは、複写サービスへと進むことができる。