Deep Learning for Natural Language Processing¶
Outline¶
- Use-case: Recognizing Textual Entailment
- Conditional Encoding
- Attention
- Bag of Tricks
- Continuous Optimization
- Regularization
- Hyper-parameter Optimization
- Pre-trained Representations
- Batching
- Bucketing
- TensorFlow
dynamic_rnn - Bi-directional RNNs
Recognizing Textual Entailment (RTE)¶
- A wedding party is taking pictures
- There is a funeral : Contradiction
- They are outside : Neutral
- Someone got married : Entailment
State of the Art until 2015¶
[Lai and Hockenmaier, 2014, Jimenez et al., 2014, Zhao et al., 2014, Beltagy et al., 2015 etc.]
- Engineered natural language processing pipelines
- Various external resources
- Specialized subcomponents
- Extensive manual creation of features:
- Negation detection, word overlap, part-of-speech tags, dependency parses, alignment, unaligned matching, chunk alignment, synonym, hypernym, antonym, denotation graph
Neural Networks for RTE¶
Previous RTE corpora:
- Tiny data sets (1k-10k examples)
- Partly synthetic examples
Stanford Natural Inference Corpus (SNLI):
- 500k sentence pairs
- Two orders of magnitude larger than existing RTE data set
- All examples generated by humans
Independent Sentence Encoding¶
[Bowman et al, 2015]
Same LSTM encodes premise and hypothesis

Independent Sentence Encoding¶
[Bowman et al, 2015]
Same LSTM encodes premise and hypothesis

You can’t cram the meaning of a whole
%&!$# sentence into a single $&!#* vector!
-- Raymond J. Mooney
Independent Sentence Encoding¶
[Bowman et al, 2015]

TensorFlow: Multi-layer Perceptron¶
In [4]:
with tf.Graph().as_default():
def mlp(input_vector, layers=3, hidden_dim=200, output_dim=3):
# [input_size] => [input_size x 1] (column vector)
tmp = tf.expand_dims(input_vector, 1)
for i in range(layers+1):
W = tf.get_variable(
"W_"+str(i), [hidden_dim, hidden_dim])
# tanh(Wx^T)
tmp = tf.tanh(tf.matmul(W, tmp))
W = tf.get_variable(
"W_"+str(layers+1), [output_dim, hidden_dim])
# [input_size x 1] => [input_size]
return tf.squeeze(tf.matmul(W, tmp))
premise = tf.placeholder(tf.float32, [None], "premise")
hypothesis = tf.placeholder(tf.float32, [None], "hypothesis")
output = tf.nn.softmax(mlp(tf.concat([premise, hypothesis], axis=0)))
# in practice: outputs of an LSTM
v1 = np.random.rand(100); v2 = np.random.rand(100)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(output, {premise: v1, hypothesis: v2}))
[ 0.28892419 0.30673885 0.40433696]
Results¶
| Model | k | θW+M | θM | Train | Dev | Test |
|---|---|---|---|---|---|---|
| LSTM [Bowman et al.] | 100 | $\approx$10M | 221k | 84.4 | - | 77.6 |
| Classifier [Bowman et al.] | - | - | - | 99.7 | - | 78.2 |
Conditional Endcoding¶

\begin{align}
\text{softmax}(\text{tanh}(\mathbf{W}\mathbf{h}_N))
\end{align}
Conditional Endcoding¶

\begin{align}
\text{softmax}(\text{tanh}(\mathbf{W}\mathbf{h}_N))
\end{align}
Results¶
| Model | k | θW+M | θM | Train | Dev | Test |
|---|---|---|---|---|---|---|
| LSTM [Bowman et al.] | 100 | $\approx$10M | 221k | 84.4 | - | 77.6 |
| Classifier [Bowman et al.] | - | - | - | 99.7 | - | 78.2 |
| Conditional Endcoding | 159 | 3.9M | 252k | 84.4 | 83.0 | 81.4 |
Attention [Graves 2013, Bahdanau et al. 2015]

\begin{align}
\mathbf{M} &= \tanh(\mathbf{W}^y\mathbf{Y}+ \mathbf{W}^h\mathbf{h}_N\mathbf{1}^T_L)&\mathbf{M}&\in\mathbb{R}^{k \times L}\\
\alpha &= \text{softmax}(\mathbf{w}^T\mathbf{M})&\alpha&\in\mathbb{R}^L\\
\mathbf{r} &= \mathbf{Y}\alpha^T&\mathbf{r}&\in\mathbb{R}^k
\end{align}
Attention [Graves 2013, Bahdanau et al. 2015]

\begin{align}
\mathbf{M} &= \tanh(\mathbf{W}^y\mathbf{Y}+ \mathbf{W}^h\mathbf{h}_N\mathbf{1}^T_L)&\mathbf{M}&\in\mathbb{R}^{k \times L}\\
\alpha &= \text{softmax}(\mathbf{w}^T\mathbf{M})&\alpha&\in\mathbb{R}^L\\
\mathbf{r} &= \mathbf{Y}\alpha^T&\mathbf{r}&\in\mathbb{R}^k
\end{align}

Contextual Understanding¶

Results¶
| Model | k | θW+M | θM | Train | Dev | Test |
|---|---|---|---|---|---|---|
| LSTM [Bowman et al.] | 100 | $\approx$10M | 221k | 84.4 | - | 77.6 |
| Classifier [Bowman et al.] | - | - | - | 99.7 | - | 78.2 |
| Conditional Encoding | 159 | 3.9M | 252k | 84.4 | 83.0 | 81.4 |
| Attention | 100 | 3.9M | 242k | 85.4 | 83.2 | 82.3 |
Fuzzy Attention¶

Word-by-word Attention [Bahdanau et al. 2015, Hermann et al. 2015, Rush et al. 2015]

\begin{align}
\mathbf{M}_t &= \tanh(\mathbf{W}^y\mathbf{Y}+(\mathbf{W}^h\mathbf{h}_t+\mathbf{W}^r\mathbf{r}_{t-1})\mathbf{1}^T_L) & \mathbf{M}_t &\in\mathbb{R}^{k\times L}\\
\alpha_t &= \text{softmax}(\mathbf{w}^T\mathbf{M}_t)&\alpha_t&\in\mathbb{R}^L\\
\mathbf{r}_t &= \mathbf{Y}\alpha^T_t + \tanh(\mathbf{W}^t\mathbf{r}_{t-1})&\mathbf{r}_t&\in\mathbb{R}^k
\end{align}
Word-by-word Attention [Bahdanau et al. 2015, Hermann et al. 2015, Rush et al. 2015]

\begin{align}
\mathbf{M}_t &= \tanh(\mathbf{W}^y\mathbf{Y}+(\mathbf{W}^h\mathbf{h}_t+\mathbf{W}^r\mathbf{r}_{t-1})\mathbf{1}^T_L) & \mathbf{M}_t &\in\mathbb{R}^{k\times L}\\
\alpha_t &= \text{softmax}(\mathbf{w}^T\mathbf{M}_t)&\alpha_t&\in\mathbb{R}^L\\
\mathbf{r}_t &= \mathbf{Y}\alpha^T_t + \tanh(\mathbf{W}^t\mathbf{r}_{t-1})&\mathbf{r}_t&\in\mathbb{R}^k
\end{align}
Reordering¶

Garbage Can = Trashcan¶

Kids = Girl + Boy¶

Snow is outside¶

Results¶
| Model | k | θW+M | θM | Train | Dev | Test |
|---|---|---|---|---|---|---|
| LSTM [Bowman et al.] | 100 | $\approx$10M | 221k | 84.4 | - | 77.6 |
| Classifier [Bowman et al.] | - | - | - | 99.7 | - | 78.2 |
| Conditional Encoding | 159 | 3.9M | 252k | 84.4 | 83.0 | 81.4 |
| Attention | 100 | 3.9M | 242k | 85.4 | 83.2 | 82.3 |
| Word-by-word Attention | 100 | 3.9M | 252k | 85.3 | 83.7 | 83.5 |
Bag of Tricks¶
Continuous Optimization¶
 Source: Wikipedia
Source: Wikipedia
Momentum¶

TensorFlow: Optimizers¶
- GradientDescent
- RMSProp
- Adagrad
- Adadelta
- Adam
In [5]:
with tf.Graph().as_default():
x = tf.get_variable("param", [])
loss = -tf.log(tf.sigmoid(x)) # dummy example
optim = tf.train.AdamOptimizer(learning_rate=0.1)
min_op = optim.minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(x.assign(1.5))
for i in range(10):
print(sess.run([min_op, loss], {})[1])
0.201413 0.183901 0.167832 0.153134 0.139727 0.127529 0.116455 0.106421 0.0973447 0.0891449
Gradient Clipping¶

In [6]:
with tf.Graph().as_default():
x = tf.get_variable("param", [])
loss = -tf.log(tf.sigmoid(x)) # dummy example
optim = tf.train.AdamOptimizer(learning_rate=0.1)
gradients = optim.compute_gradients(loss)
capped_gradients = \
[(tf.clip_by_value(grad, -0.1, 0.1), var) for grad, var in gradients]
min_op = optim.apply_gradients(capped_gradients)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()); sess.run(x.assign(1.5))
for i in range(100):
if i % 10 == 0:
grads = sess.run([min_op, gradients, capped_gradients], {})[1:]
print(" => ".join([str(grad[0][0]) for grad in grads]))
-0.182426 => -0.1 -0.167982 => -0.1 -0.154465 => -0.1 -0.141851 => -0.1 -0.130109 => -0.1 -0.119203 => -0.1 -0.109097 => -0.1 -0.0997508 => -0.0997508 -0.0911243 => -0.0911243 -0.0832129 => -0.0832129
Regularization¶

In [7]:
with tf.Graph().as_default():
x = tf.placeholder(tf.float32, [None], "input")
x_dropped = tf.nn.dropout(x, 0.7) # keeps 70% of values
with tf.Session() as sess:
print(sess.run(x_dropped, {x: np.random.rand(6)}))
[ 0. 0.40834624 1.31100929 0. 1.08233535 0. ]
Early Stopping¶

Hyper-parameter Optimization¶
[Bergstra and Bengio 2012]
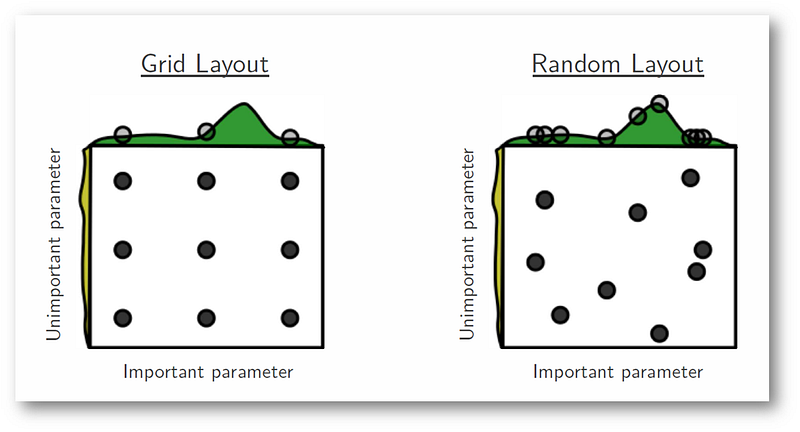
Pre-trained Representations¶
In [8]:
with tf.Graph().as_default():
vocab_size = 4; embedding_size = 3
W = tf.get_variable("W", [vocab_size, embedding_size], trainable=False)
W = W.assign(np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]]))
seq = tf.placeholder(tf.int64, [None], "seq")
seq_embedded = tf.nn.embedding_lookup(W, seq)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(seq_embedded, {seq:[0, 3, 2, 3, 1]})[2])
[ 6. 7. 8.]
Projecting Representations¶
In [9]:
with tf.Graph().as_default():
vocab_size = 4; embedding_size = 3; input_size = 2
W = tf.get_variable("W", [vocab_size, embedding_size], trainable=False)
W = W.assign(np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]]))
seq = tf.placeholder(tf.int64, [None], "seq")
seq_embedded = tf.contrib.layers.linear(tf.nn.embedding_lookup(W, seq), input_size)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(seq_embedded, {seq:[0, 3, 2, 3, 1]})[2])
[-13.46509552 2.99458957]



In [10]:
with tf.Graph().as_default():
input_size = 2; output_size = 3; batch_size = 5; max_length = 7
cell = tf.nn.rnn_cell.LSTMCell(output_size)
input_embedded = tf.placeholder(tf.float32, [None, None, input_size], "input_embedded")
input_length = tf.placeholder(tf.int64, [None], "input_length")
outputs, states = \
tf.nn.dynamic_rnn(cell, input_embedded, sequence_length=input_length, dtype=tf.float32)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(states, {
input_embedded: np.random.randn(batch_size, max_length, input_size),
input_length: np.random.randint(1, max_length, batch_size)
}).h)
[[-0.02504479 0.01778306 0.06259364] [-0.39973924 0.15913689 -0.24309666] [ 0.1272437 -0.11015443 0.27061945] [-0.16756612 0.08985849 -0.09469282] [-0.31299666 0.21844 -0.0656506 ]]
