 #
# # Getting started with the DBpedia SPARQL endpoint
#
# In this episode I begin to explore the DBpedia public SPARQL endpoint. I'll go through the following stages
#
# * setting up tools
# * counting triples
# * counting predicates
# * examination of the predicate **pr:skipperlastname**
# * countings classes
# * examination of the class **on:CareerStation**
#
# My method is a deliberate combination of systematic analysis (looking at counts, methods that can applied to arbitrary predicates or classes) and opportunism
# (looking at topics that catch my eye.) DBpedia is too heterogenous to characterize in one article, but I'll begin to uncover the dark art of writing SPARQL queries against generic databases.
#
# ## Setting up tools
#
# A first step is to import a number of symbols that we'll use to do SPARQL queries and visualize the result
# In[1]:
import sys
from gastrodon import RemoteEndpoint,QName,ttl,URIRef,inline
import pandas as pd
pd.options.display.width=120
pd.options.display.max_colwidth=100
# First I'll define a few prefixes for namespaces that I want to use.
# In[2]:
prefixes=inline("""
@prefix :
#
# # Getting started with the DBpedia SPARQL endpoint
#
# In this episode I begin to explore the DBpedia public SPARQL endpoint. I'll go through the following stages
#
# * setting up tools
# * counting triples
# * counting predicates
# * examination of the predicate **pr:skipperlastname**
# * countings classes
# * examination of the class **on:CareerStation**
#
# My method is a deliberate combination of systematic analysis (looking at counts, methods that can applied to arbitrary predicates or classes) and opportunism
# (looking at topics that catch my eye.) DBpedia is too heterogenous to characterize in one article, but I'll begin to uncover the dark art of writing SPARQL queries against generic databases.
#
# ## Setting up tools
#
# A first step is to import a number of symbols that we'll use to do SPARQL queries and visualize the result
# In[1]:
import sys
from gastrodon import RemoteEndpoint,QName,ttl,URIRef,inline
import pandas as pd
pd.options.display.width=120
pd.options.display.max_colwidth=100
# First I'll define a few prefixes for namespaces that I want to use.
# In[2]:
prefixes=inline("""
@prefix : 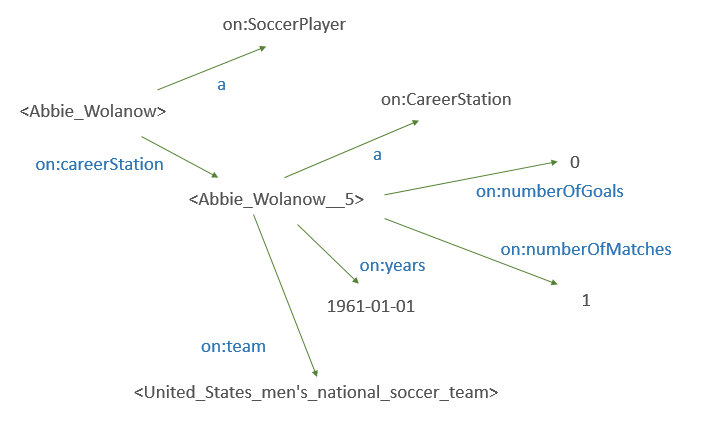 #
# and this a general pattern for how one might deal with situations where we want to say something more complex than "Abbie Wolanow played for the U.S. Men's National Soccer Team".
#
# In terms of the source data, Career stations are much like the race entries in the yachting example in that a single page on Wikipedia contains a number of "sub-topics" that need to be referred to in order to keep together facts such as "**this boat** was the third finisher" and "Cam Lewis was the skipper of **this boat**"
#
# The difference is that DBpedia identifies individual career stations while it does not indentify individual race entries.
# Here is a survey of the different predicate types that are used to
# describe career stations. I was probably a bit unlucky to pick a player who didn't have **on:years** specified very often:
# In[34]:
endpoint.select("""
SELECT ?p (COUNT(*) AS ?count) {
?that a on:CareerStation .
?that ?p ?o .
} GROUP BY ?p ORDER BY DESC(?count)
""")
# What sort of people have career stations? I count the career stations and get the following results:
# In[35]:
pd.options.display.max_rows=20
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
?station a on:CareerStation .
?who on:careerStation ?station .
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
# Career stations seem heavily weighted towards people who play soccer! The numbers above are hard to compare to other characteristics, however, because they are counting the career stations instead of the people. For instance, Abbie Wolanow is counted five times because he has five career stations.
#
# With a slightly different query, I can count the actual number of people of various types who have career stations.
# In[36]:
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
{ SELECT DISTINCT ?who {
?station a on:CareerStation .
?who on:careerStation ?station .
} }
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
# Note that the counts here do not need to add up to anything in particular, because it is possible for someone to be in more than one category at a time. For instance, we see the same count for `on:Person` and `on:Agent` as well as `on:Athlete` and `on:SoccerPlayer` because each soccer player is an athlete. I got suspicious, however, and found that if I added the number of soccer players to the number of soccer managers...
# In[37]:
18617+117270
# ... and found they were equal! That suggests that all of the people with career stations are involved with soccer, and that **on:SoccerPlayer** and **on:SoccerManager** are mutually exclusive.
#
# I test that mutually exclusive bit by counting the number of topics which are both soccer players and soccer managers:
# In[38]:
endpoint.select("""
SELECT (COUNT(*) AS ?count) {
?x a on:SoccerPlayer .
?x a on:SoccerManager .
}
""")
# Those two really are mutually exclusive.
#
# This seems strange to me. I don't know much about soccer (I am from the U.S. after all!) but frequently coaches and team managers are former players in other sports, shoudn't they be in soccer?
#
# I investigate just a bit more, first getting a sample of managers...
# In[39]:
endpoint.select("""
SELECT ?x {
?x a on:SoccerManager .
} LIMIT 10
""")
# ... and then looking at the text description of one in particular:
# In[40]:
endpoint.select("""
SELECT ?comment {
#
# and this a general pattern for how one might deal with situations where we want to say something more complex than "Abbie Wolanow played for the U.S. Men's National Soccer Team".
#
# In terms of the source data, Career stations are much like the race entries in the yachting example in that a single page on Wikipedia contains a number of "sub-topics" that need to be referred to in order to keep together facts such as "**this boat** was the third finisher" and "Cam Lewis was the skipper of **this boat**"
#
# The difference is that DBpedia identifies individual career stations while it does not indentify individual race entries.
# Here is a survey of the different predicate types that are used to
# describe career stations. I was probably a bit unlucky to pick a player who didn't have **on:years** specified very often:
# In[34]:
endpoint.select("""
SELECT ?p (COUNT(*) AS ?count) {
?that a on:CareerStation .
?that ?p ?o .
} GROUP BY ?p ORDER BY DESC(?count)
""")
# What sort of people have career stations? I count the career stations and get the following results:
# In[35]:
pd.options.display.max_rows=20
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
?station a on:CareerStation .
?who on:careerStation ?station .
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
# Career stations seem heavily weighted towards people who play soccer! The numbers above are hard to compare to other characteristics, however, because they are counting the career stations instead of the people. For instance, Abbie Wolanow is counted five times because he has five career stations.
#
# With a slightly different query, I can count the actual number of people of various types who have career stations.
# In[36]:
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
{ SELECT DISTINCT ?who {
?station a on:CareerStation .
?who on:careerStation ?station .
} }
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
# Note that the counts here do not need to add up to anything in particular, because it is possible for someone to be in more than one category at a time. For instance, we see the same count for `on:Person` and `on:Agent` as well as `on:Athlete` and `on:SoccerPlayer` because each soccer player is an athlete. I got suspicious, however, and found that if I added the number of soccer players to the number of soccer managers...
# In[37]:
18617+117270
# ... and found they were equal! That suggests that all of the people with career stations are involved with soccer, and that **on:SoccerPlayer** and **on:SoccerManager** are mutually exclusive.
#
# I test that mutually exclusive bit by counting the number of topics which are both soccer players and soccer managers:
# In[38]:
endpoint.select("""
SELECT (COUNT(*) AS ?count) {
?x a on:SoccerPlayer .
?x a on:SoccerManager .
}
""")
# Those two really are mutually exclusive.
#
# This seems strange to me. I don't know much about soccer (I am from the U.S. after all!) but frequently coaches and team managers are former players in other sports, shoudn't they be in soccer?
#
# I investigate just a bit more, first getting a sample of managers...
# In[39]:
endpoint.select("""
SELECT ?x {
?x a on:SoccerManager .
} LIMIT 10
""")
# ... and then looking at the text description of one in particular:
# In[40]:
endpoint.select("""
SELECT ?comment {
 #
#
#
#
#
#
#
#
#
# |
#
# This article is part of a series. # Subscribe to my mailing list to be notified when new installments come out. # # # # |
#