#!/usr/bin/env python
# coding: utf-8
# Machine Learning Lunch
#
# Tom Brander
# June 28, 2017
#
#
#
#
#
#
# ## Many Thanks to [Compose](https://compose.com/) for the space and lunch!
#
# ### http://oswco.com [@dartdog](https://twitter.com/dartdog)
#
#
# The PyData Stack
# Source: [Jake VanderPlas: State of the Tools](https://www.youtube.com/watch?v=5GlNDD7qbP4)
# and [Thomas Wiecki](https://quantopian.github.io/pyfolio/)
#  # To the uninitiated the whole pile of Python stuff looks terribly complicated.
# To some extent it is.
# But there has been a ton of work done to bring order out of the apparent chaos!
# # The Libraries (just a starting point)
#
# + Python, of course (https://www.python.org/)
# - A few years ago there was a change from the the Python 2, series to the Python 3 series
# - Now the recomendation is just go with Python 3.6
# + Pandas (http://pandas.pydata.org/)
# - Main data manipulation library, mostly using DataFrames (think Excel on steroids)
# - Many IO capabilities GBQ, S-3, Parquet, SQL, CSV, JSON, And web data (stock prices and financial data)
# - Built on top of Numpy
#
# + Numpy (http://www.numpy.org/)
# - High performance numerical library particularly array and matrix oriented
# + Matplotlib (https://matplotlib.org/)
# - the grand daddy of Python Plotting libraries, many other libraries build on it to simplify and or stylize it
# + Sci-kit Learn (http://scikit-learn.org/stable/)
# - A collection of libraries for almost all types of machine learning with consitant API's and supporting libraries
# + TensorFlow (https://www.tensorflow.org/)
# - Google's open source numerical computing library
# - on which they have built and released a large number of machine learning components
# - along with a number of supporting components (I/O, encoding, serving etc)
# + Keras (https://keras.io/)(https://www.tensorflow.org/api_docs/python/tf/contrib/keras)
# - a simplified interface to many Machine learning libraries, also incorporated into TensorFlow
# - supports Theano, Cntk, Pytorch (and more on the way)
# + StatsModels (http://www.statsmodels.org/stable/index.html)(https://patsy.readthedocs.io/en/latest/)
# - Many statistical techniques and the Patsy statistical language (much like R)
# + PyMC3 (https://pymc-devs.github.io/pymc3/index.html)
# - Baysian Modeling library (in many ways comparable to Stan but newer)
# ## Jupyter
# + (http://jupyter.org/)
# + What this notebook is done with
# + Has become a common format for "open data Science"
# + Has also become a great method for shaing code and documentation throughout the Python community
# + Supports many other languages, or Kernels R, Julia (a newer stats language) Go, Ruby ++ In many cases allows easier interoperabilitty between them
# # Anaconda
# + (https://www.continuum.io/anaconda-overview)
# + All of the above,(150+ libraries), (except TensorFlow/Keras) and much more is auto installed for you using the Anaconda distribution including a nice IDE, Spyder
# + As a bonus you get a faster than "Normal" version of Python with Intel MKL extensions built in
# - Speed-boosted NumPy, SciPy, scikit-learn, and NumExpr
# - The packaging of MKL with redistributable binaries in Anaconda for easy access to the MKL runtime library.
# - Python bindings to the low level MKL service functions, which allow for the modification of the number of threads being used during runtime.
#
# # Books
# + Data Science Handbook, freely available on GitHub, excellent resource https://github.com/jakevdp/PythonDataScienceHandbook
# + Python Machine Learning by Sebastian Raschka https://www.packtpub.com/big-data-and-business-intelligence/python-machine-learning Primarily Sci-Kit learn Highly Recommeded!
# + Hands-On Machine Learning with Scikit-Learn and TensorFlow by Aurélien Géron http://shop.oreilly.com/product/0636920052289.do
# + Deep Learning with Python by Francois Chollet https://www.manning.com/books/deep-learning-with-python
# # Five More Tips
# + Jupyter Notebook Gallery, Awesome https://github.com/jupyter/jupyter/wiki/A-gallery-of-interesting-Jupyter-Notebooks
# + CSVKIT (https://csvkit.readthedocs.io/en/1.0.2/)
# + Pandas profiling (https://github.com/JosPolfliet/pandas-profiling)
# + Kaggle (https://www.kaggle.com/)
# + What type of algorithim? (http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
# # Course
# + https://github.com/amueller/scipy-2016-sklearn Videos and notebooks
# # Machine Learning:
#
#
# To the uninitiated the whole pile of Python stuff looks terribly complicated.
# To some extent it is.
# But there has been a ton of work done to bring order out of the apparent chaos!
# # The Libraries (just a starting point)
#
# + Python, of course (https://www.python.org/)
# - A few years ago there was a change from the the Python 2, series to the Python 3 series
# - Now the recomendation is just go with Python 3.6
# + Pandas (http://pandas.pydata.org/)
# - Main data manipulation library, mostly using DataFrames (think Excel on steroids)
# - Many IO capabilities GBQ, S-3, Parquet, SQL, CSV, JSON, And web data (stock prices and financial data)
# - Built on top of Numpy
#
# + Numpy (http://www.numpy.org/)
# - High performance numerical library particularly array and matrix oriented
# + Matplotlib (https://matplotlib.org/)
# - the grand daddy of Python Plotting libraries, many other libraries build on it to simplify and or stylize it
# + Sci-kit Learn (http://scikit-learn.org/stable/)
# - A collection of libraries for almost all types of machine learning with consitant API's and supporting libraries
# + TensorFlow (https://www.tensorflow.org/)
# - Google's open source numerical computing library
# - on which they have built and released a large number of machine learning components
# - along with a number of supporting components (I/O, encoding, serving etc)
# + Keras (https://keras.io/)(https://www.tensorflow.org/api_docs/python/tf/contrib/keras)
# - a simplified interface to many Machine learning libraries, also incorporated into TensorFlow
# - supports Theano, Cntk, Pytorch (and more on the way)
# + StatsModels (http://www.statsmodels.org/stable/index.html)(https://patsy.readthedocs.io/en/latest/)
# - Many statistical techniques and the Patsy statistical language (much like R)
# + PyMC3 (https://pymc-devs.github.io/pymc3/index.html)
# - Baysian Modeling library (in many ways comparable to Stan but newer)
# ## Jupyter
# + (http://jupyter.org/)
# + What this notebook is done with
# + Has become a common format for "open data Science"
# + Has also become a great method for shaing code and documentation throughout the Python community
# + Supports many other languages, or Kernels R, Julia (a newer stats language) Go, Ruby ++ In many cases allows easier interoperabilitty between them
# # Anaconda
# + (https://www.continuum.io/anaconda-overview)
# + All of the above,(150+ libraries), (except TensorFlow/Keras) and much more is auto installed for you using the Anaconda distribution including a nice IDE, Spyder
# + As a bonus you get a faster than "Normal" version of Python with Intel MKL extensions built in
# - Speed-boosted NumPy, SciPy, scikit-learn, and NumExpr
# - The packaging of MKL with redistributable binaries in Anaconda for easy access to the MKL runtime library.
# - Python bindings to the low level MKL service functions, which allow for the modification of the number of threads being used during runtime.
#
# # Books
# + Data Science Handbook, freely available on GitHub, excellent resource https://github.com/jakevdp/PythonDataScienceHandbook
# + Python Machine Learning by Sebastian Raschka https://www.packtpub.com/big-data-and-business-intelligence/python-machine-learning Primarily Sci-Kit learn Highly Recommeded!
# + Hands-On Machine Learning with Scikit-Learn and TensorFlow by Aurélien Géron http://shop.oreilly.com/product/0636920052289.do
# + Deep Learning with Python by Francois Chollet https://www.manning.com/books/deep-learning-with-python
# # Five More Tips
# + Jupyter Notebook Gallery, Awesome https://github.com/jupyter/jupyter/wiki/A-gallery-of-interesting-Jupyter-Notebooks
# + CSVKIT (https://csvkit.readthedocs.io/en/1.0.2/)
# + Pandas profiling (https://github.com/JosPolfliet/pandas-profiling)
# + Kaggle (https://www.kaggle.com/)
# + What type of algorithim? (http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
# # Course
# + https://github.com/amueller/scipy-2016-sklearn Videos and notebooks
# # Machine Learning:
#
#
#  #
#
# # Skills
#
#
#
#
# # Skills
#
#
# 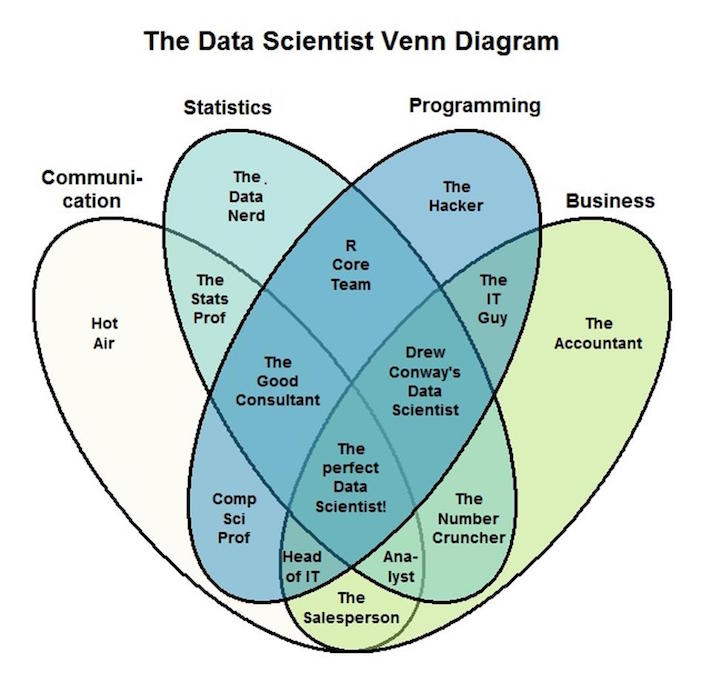 #
# From: https://opendatascience.com/blog/what-is-data-science-and-what-does-a-data-scientist-do/
# In[1]:
from tpot import TPOTClassifier
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=7, population_size=100, verbosity=2, random_state=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
# In[2]:
proc=pd.DataFrame(tpot.evaluated_individuals_)
proc.head()
# # Other links
# + Tpot http://rhiever.github.io/tpot/
# + Some new Nvidia developments https://devblogs.nvidia.com/parallelforall/goai-open-gpu-accelerated-data-analytics/
# + State of the art Medical example https://fluforecaster.herokuapp.com/
# +Initial data explore http://localhost:8889/notebooks/Documents/InfluenceH/Working_copies/Cond_fcast_wkg/ccsProfileInitialanalyis.ipynb
# +current model
# http://localhost:8889/notebooks/Documents/InfluenceH/Working_copies/Cond_fcast_wkg/WIPNNModelonehottarget2.ipynb#
# + RE forecast https://docs.google.com/spreadsheets/d/1HJxK82QYeYO13hQGaAg3hw4a4j8s0lSGdfk4BBjzh38/edit#gid=3
# + RE survey http://d1ambw9zjiu0uw.cloudfront.net/custom_reports3/21.pdf?1491572271
# + stock example http://localhost:8888/notebooks/Documents/pyfolio_wkng/examples/single_stock_example.ipynb# BUT! see issues https://github.com/quantopian/empyrical/issues/52
# + Old CCS propensity http://localhost:8888/notebooks/Documents/InfluenceH/Working_copies/CCS_wking/MultiCCS_PropModel_Div.ipynb
# + beginning CCS NN http://localhost:8888/notebooks/Documents/InfluenceH/influence/USF_elu_downsample_1.1.ipynb
# + Zillow initial explore http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/frkagnotebook.ipynb
# + Zillow Bayes initial look http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/zillow_bayes.ipynb From: http://willwolf.io/2017/06/15/random-effects-neural-networks/
# + Zillow initial Profile http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/ProfileInitialanalyis.ipynb
# + Zillow R initial profile https://www.kaggle.com/philippsp/exploratory-analysis-zillow
# + Stock trading https://github.com/Kacawi/datacamp-community and https://medium.com/datacamp/python-for-finance-algorithmic-trading-60fdfb9bb20d
# + Large collection of NN/NLP resourcs https://unsupervisedmethods.com/over-150-of-the-best-machine-learning-nlp-and-python-tutorials-ive-found-ffce2939bd78
# This notebook on Jupyter hub http://nbviewer.jupyter.org/github/dartdog/ML-lunch/blob/master/ML_resources.ipynb
# R vs Python (2 pages ) http://www.kdnuggets.com/2017/06/ecosystem-data-science-machine-learning-software.html
# In[2]:
get_ipython().run_line_magic('load_ext', 'watermark')
# In[3]:
get_ipython().run_line_magic('watermark', '-a "Tom Brander" -u -n -t -z -v -m -p pandas,numpy,scipy,sklearn,tpot,tensorflow -g')
# In[8]:
get_ipython().system('nvidia-smi')
# In[10]:
get_ipython().system('nvcc --version')
# In[11]:
get_ipython().system('cat /proc/driver/nvidia/version')
# Best basic book Mainly SciKit Learn https://www.packtpub.com/big-data-and-business-intelligence/python-machine-learning Very useful for all Python ML stuff and algorithims and what to use when and where..
#
# This still early release but the best for Keras (written by the guy who also conceived and wrote the library itself) https://www.manning.com/books/deep-learning-with-python
#
# Best book for TensorFlow http://shop.oreilly.com/product/0636920052289.do also conversely uses SciKit learn, as a method to explain some of the concepts in TF.. Highly recommended..
#
# Most accessible code can be found with Jupyter examples so you want to get that set up on your machine http://jupyter.org/
#
# Easiest way to get everything you need and keep up to date is Anaconda https://www.continuum.io/downloads Includes Jupyter mentioned above as well as Spyder a Python IDE (Win Linux And Mac) Don't even think of doing another way.. (you will thank me!)
#
# up front data exploration CSV kit https://csvkit.readthedocs.io/en/1.0.2/ specifically csvstat (lots more there though) including some god transition and report stuff..
#
# I like https://github.com/JosPolfliet/pandas-profiling
#
# Oh yes now a days just start with python 3.6 not 2.7
# In[ ]:
#
# From: https://opendatascience.com/blog/what-is-data-science-and-what-does-a-data-scientist-do/
# In[1]:
from tpot import TPOTClassifier
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=7, population_size=100, verbosity=2, random_state=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
# In[2]:
proc=pd.DataFrame(tpot.evaluated_individuals_)
proc.head()
# # Other links
# + Tpot http://rhiever.github.io/tpot/
# + Some new Nvidia developments https://devblogs.nvidia.com/parallelforall/goai-open-gpu-accelerated-data-analytics/
# + State of the art Medical example https://fluforecaster.herokuapp.com/
# +Initial data explore http://localhost:8889/notebooks/Documents/InfluenceH/Working_copies/Cond_fcast_wkg/ccsProfileInitialanalyis.ipynb
# +current model
# http://localhost:8889/notebooks/Documents/InfluenceH/Working_copies/Cond_fcast_wkg/WIPNNModelonehottarget2.ipynb#
# + RE forecast https://docs.google.com/spreadsheets/d/1HJxK82QYeYO13hQGaAg3hw4a4j8s0lSGdfk4BBjzh38/edit#gid=3
# + RE survey http://d1ambw9zjiu0uw.cloudfront.net/custom_reports3/21.pdf?1491572271
# + stock example http://localhost:8888/notebooks/Documents/pyfolio_wkng/examples/single_stock_example.ipynb# BUT! see issues https://github.com/quantopian/empyrical/issues/52
# + Old CCS propensity http://localhost:8888/notebooks/Documents/InfluenceH/Working_copies/CCS_wking/MultiCCS_PropModel_Div.ipynb
# + beginning CCS NN http://localhost:8888/notebooks/Documents/InfluenceH/influence/USF_elu_downsample_1.1.ipynb
# + Zillow initial explore http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/frkagnotebook.ipynb
# + Zillow Bayes initial look http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/zillow_bayes.ipynb From: http://willwolf.io/2017/06/15/random-effects-neural-networks/
# + Zillow initial Profile http://localhost:8888/notebooks/Documents/Zillow_w/Notebooks/ProfileInitialanalyis.ipynb
# + Zillow R initial profile https://www.kaggle.com/philippsp/exploratory-analysis-zillow
# + Stock trading https://github.com/Kacawi/datacamp-community and https://medium.com/datacamp/python-for-finance-algorithmic-trading-60fdfb9bb20d
# + Large collection of NN/NLP resourcs https://unsupervisedmethods.com/over-150-of-the-best-machine-learning-nlp-and-python-tutorials-ive-found-ffce2939bd78
# This notebook on Jupyter hub http://nbviewer.jupyter.org/github/dartdog/ML-lunch/blob/master/ML_resources.ipynb
# R vs Python (2 pages ) http://www.kdnuggets.com/2017/06/ecosystem-data-science-machine-learning-software.html
# In[2]:
get_ipython().run_line_magic('load_ext', 'watermark')
# In[3]:
get_ipython().run_line_magic('watermark', '-a "Tom Brander" -u -n -t -z -v -m -p pandas,numpy,scipy,sklearn,tpot,tensorflow -g')
# In[8]:
get_ipython().system('nvidia-smi')
# In[10]:
get_ipython().system('nvcc --version')
# In[11]:
get_ipython().system('cat /proc/driver/nvidia/version')
# Best basic book Mainly SciKit Learn https://www.packtpub.com/big-data-and-business-intelligence/python-machine-learning Very useful for all Python ML stuff and algorithims and what to use when and where..
#
# This still early release but the best for Keras (written by the guy who also conceived and wrote the library itself) https://www.manning.com/books/deep-learning-with-python
#
# Best book for TensorFlow http://shop.oreilly.com/product/0636920052289.do also conversely uses SciKit learn, as a method to explain some of the concepts in TF.. Highly recommended..
#
# Most accessible code can be found with Jupyter examples so you want to get that set up on your machine http://jupyter.org/
#
# Easiest way to get everything you need and keep up to date is Anaconda https://www.continuum.io/downloads Includes Jupyter mentioned above as well as Spyder a Python IDE (Win Linux And Mac) Don't even think of doing another way.. (you will thank me!)
#
# up front data exploration CSV kit https://csvkit.readthedocs.io/en/1.0.2/ specifically csvstat (lots more there though) including some god transition and report stuff..
#
# I like https://github.com/JosPolfliet/pandas-profiling
#
# Oh yes now a days just start with python 3.6 not 2.7
# In[ ]: